Rnj-1
Rnj-1
Rnj-1 is a family of 8B parameter open-weight, dense models trained from scratch by Essential AI.
Memory Requirements
To run the smallest Rnj-1, you need at least 6 GB of RAM.
Capabilities
Rnj-1 models support tool use and reasoning. They are available in gguf.
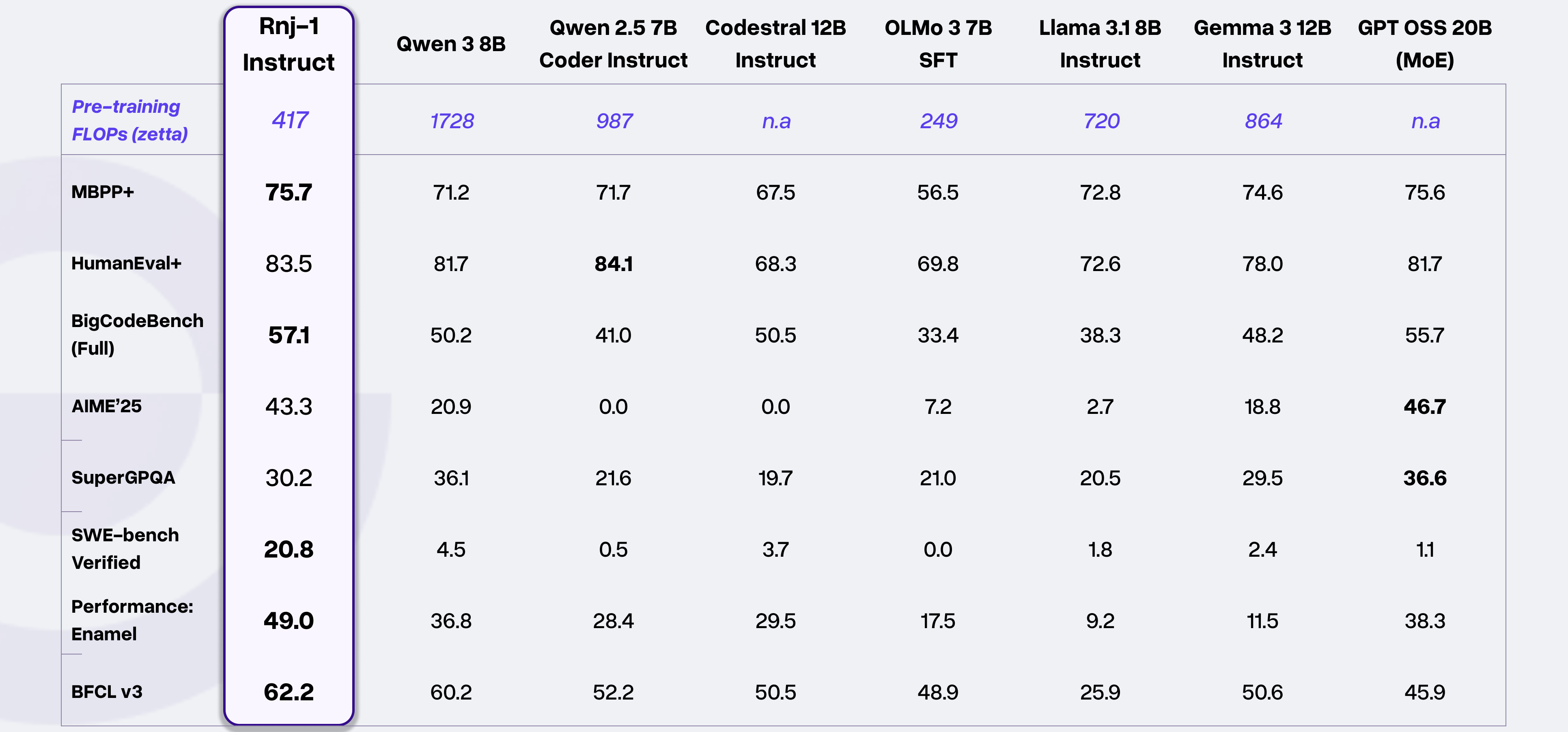
About Rnj-1

Rnj-1 is a family of 8B parameter open-weight, dense models trained from scratch by Essential AI, optimized for code and STEM with capabilities on par with SOTA open-weight models. These models perform well across a range of programming languages and boast strong agentic capabilities (e.g., inside agentic frameworks like mini-SWE-agent), while also excelling at tool-calling. They additionally exhibit strong capabilities in math and science. Herein, rnj-1 refers to the base model, while rnj-1-instruct refers to the post-trained instruction tuned model.
Note: essentialai/rnj-1 in LM Studio is the instruct variant of this model.
Capabilities
rnj-1-instruct is strong at code, math, and STEM tasks. It also performs well within agentic frameworks such as mini-swe-agent and has stellar tool use abilities.
Architecture
Rnj-1's architecture is similar to Gemma 3, except that it uses only global attention, and YaRN for long-context extension.
| Hyperparameter | Value |
|---|---|
| Total Parameters | 8.3B |
| Number of Layers | 32 |
| Model Dimension | 4096 |
| MLP Dimension | 16384 |
| Number of Attention Heads | 32 |
| Number of Key-Value Heads | 8 |
| Attention Head Dimension | 128 |
| Vocabulary Size | 128K |
| Pretrain Context Length | 8K |
| Context Length | 32K |
| Activation Function | GeGLU |
| Tied Embeddings? | Yes |
Training Dynamics
rnj-1 was pre-trained on 8.4T tokens with an 8K context length, after which the model’s context window was extended to 32K through an additional 380B-token mid-training stage. A final 150B-token SFT stage completed the training to produce rnj-1-instruct.
We used the Muon optimizer throughout all phases. Pre-training followed the WSD learning-rate schedule, consisting of:
- Warmup: Linear ramp-up from 0 to 2e-3 over the first 5K steps.
- Stable phase: Constant learning rate of 2e-3 from 5K → 230K steps.
- Decay: Cosine decay from 2e-3 → 2e-5 from 230K → 380K steps.
- Final stable phase: Constant 2e-5 learning rate from 380K → 443.5K steps, concluding pre-training.
Both the mid-training (context-extension phase) and SFT were trained at a fixed learning rate of 2e-5.
The global batch sizes used were:
- 18M tokens for pre-training.
- 24M tokens for mid-training.
- 16M tokens for SFT.
License
The model is available under the Apache-2.0 license.