Nemotron 3
Nemotron 3
General purpose reasoning and chat model trained from scratch by NVIDIA. Contains 30B total parameters with only 3.5B active at a time for low-latency MoE inference
Memory Requirements
To run the smallest Nemotron 3, you need at least 25 GB of RAM.
Capabilities
Nemotron 3 models support tool use and reasoning. They are available in gguf and mlx.
About Nemotron 3

Nemotron-3-Nano-30B-A3B-BF16 is a large language model (LLM) trained from scratch by NVIDIA, and designed as a unified model for both reasoning and non-reasoning tasks. It responds to user queries and tasks by first generating a reasoning trace and then concluding with a final response. The model's reasoning capabilities can be configured through a flag in the chat template. If the user prefers the model to provide its final answer without intermediate reasoning traces, it can be configured to do so, albeit with a slight decrease in accuracy for harder prompts that require reasoning. Conversely, allowing the model to generate reasoning traces first generally results in higher-quality final solutions to queries and tasks.
Model Architecture
- Architecture Type: Mamba2-Transformer Hybrid Mixture of Experts (MoE)
- Network Architecture: Nemotron Hybrid MoE
- Number of model parameters: 30B
Training
The model was trained with 25T tokens, with a batch size of 3072, and used the Warmup-Stable-Decay (WSD) learning rate schedule with 8B tokens of learning rate warm up, peak learning rate of 1e-3 and minimum learning rate of 1e-5. There are a total of 52 layers, of which there are 23 of each MoE and Mamba-2 and the remaining 6 layers use grouped query attention (GQA) with 2 groups. Each MoE layer has 128 routed experts, where each token activates top-6 experts, along with 2 shared experts which are activated on all tokens.
Performance
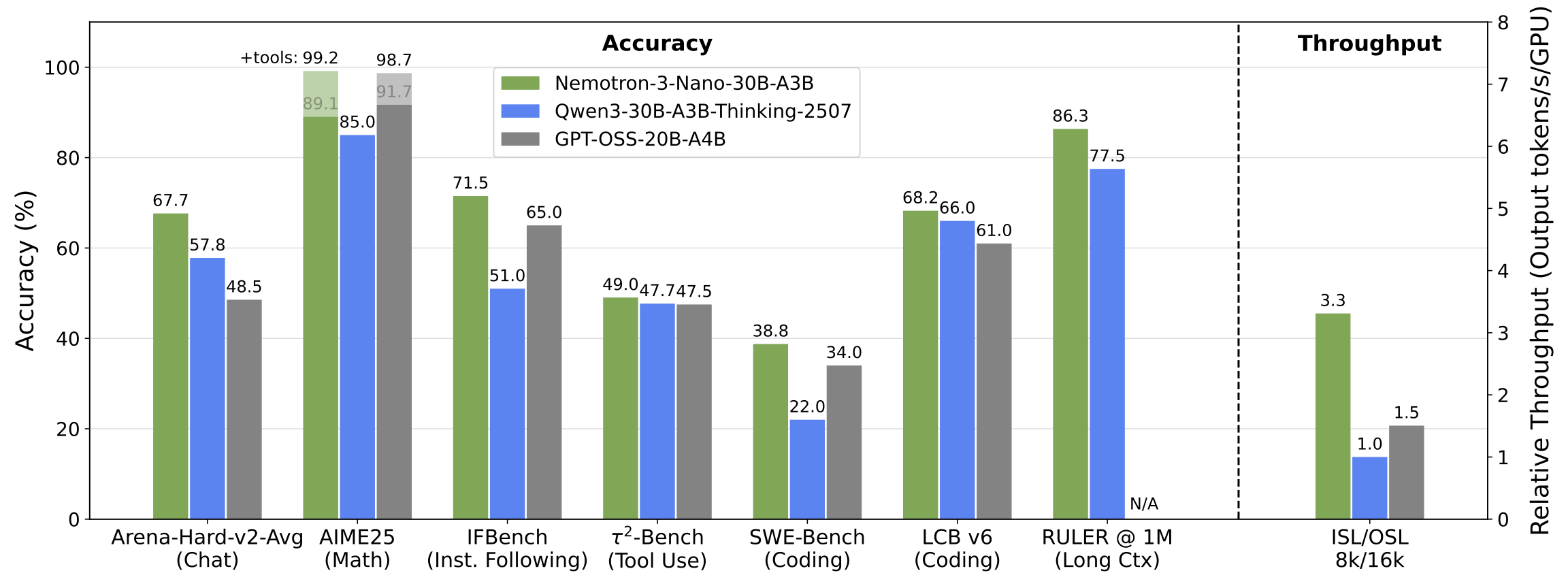
| Task | NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 | Qwen3-30B-A3B-Thinking-2507 | GPT-OSS-20B |
|---|---|---|---|
| General Knowledge | |||
| MMLU-Pro | 78.3 | 80.9 | 75.0 |
| Reasoning | |||
| AIME25 (no tools) | 89.1 | 85.0 | 91.7 |
| AIME25 (with tools) | 99.2 | - | 98.7 |
| GPQA (no tools) | 73.0 | 73.4 | 71.5 |
| GPQA (with tools) | 75.0 | - | 74.2 |
| LiveCodeBench (v6 2025-08–2025-05) | 68.3 | 66.0 | 61.0 |
| SciCode (subtask) | 33.3 | 33.0 | 34.0 |
| HLE (no tools) | 10.6 | 9.8 | 10.9 |
| HLE (with tools) | 15.5 | - | 17.3 |
| MiniF2F pass@1 | 50.0 | 5.7 | 12.1 |
| MiniF2F pass@32 | 79.9 | 16.8 | 43.0 |
| Agentic | |||
| Terminal Bench (hard subset) | 8.5 | 5.0 | 6.0 |
| SWE-Bench (OpenHands) | 38.8 | 22.0 | 34.0 |
| TauBench V2 (Airline) | 48.0 | 58.0 | 38.0 |
| TauBench V2 (Retail) | 56.9 | 58.8 | 38.0 |
| TauBench V2 (Telecom) | 42.2 | 26.3 | 49.7 |
| TauBench V2 (Average) | 49.0 | 47.7 | 48.7 |
| BFCL v4 | 53.8 | 46.4* | - |
| Chat & Instruction Following | |||
| IFBench (prompt) | 71.5 | 51.0 | 65.0 |
| Scale AI Multi Challenge | 38.5 | 44.8 | 33.8 |
| Arena-Hard-V2 (Hard Prompt) | 72.1 | 49.6* | 71.2* |
| Arena-Hard-V2 (Creative Writing) | 63.2 | 66.0* | 25.9& |
| Arena-Hard-V2 (Average) | 67.7 | 57.8 | 48.6 |
| Long Context | |||
| AA-LCR | 35.9 | 59.0 | 34.0 |
| RULER-100@256k | 92.9 | 89.4 | - |
| RULER-100@512k | 91.3 | 84.0 | - |
| RULER-100@1M | 86.3 | 77.5 | - |
| Multilingual | |||
| MMLU-ProX (avg over langs) | 59.5 | 77.6* | 69.1* |
| WMT24++ (en→xx) | 86.2 | 85.6 | 83.2 |
All evaluation results were collected via Nemo Evaluator SDK and Nemo Skills. The open source container on Nemo Skills packaged via NVIDIA's Nemo Evaluator SDK used for evaluations can be found here. In addition to Nemo Skills, the evaluations also used dedicated packaged containers for Tau-2 Bench, ArenaHard v2, AA_LCR. A reproducibility tutorial along with all configs can be found in Nemo Evaluator SDK examples. * denotes the accuracy numbers are measured by NVIDIA.
License
The Nemotron 3 model is provided under the nvidia-open-model-license