LFM2-24B-A2B
LFM2-24B-A2B
LFM2 is a family of hybrid models designed for on-device deployment. LFM2-24B-A2B is the largest model in the family, scaling the architecture to 24 billion parameters while keeping inference efficient.
Memory Requirements
To run the smallest LFM2-24B-A2B, you need at least 14 GB of RAM.
Capabilities
LFM2-24B-A2B models support tool use. They are available in gguf and mlx.
About LFM2-24B-A2B

LFM2 is a family of hybrid models designed for on-device deployment. LFM2-24B-A2B is the largest model in the family, scaling the architecture to 24 billion parameters while keeping inference efficient.
- Best-in-class efficiency: A 24B MoE model with only 2B active parameters per token, fitting in 32 GB of RAM for deployment on consumer laptops and desktops.
- Fast edge inference: 112 tok/s decode on AMD CPU, 293 tok/s on H100. Fits in 32B GB of RAM with day-one support llama.cpp, vLLM, and SGLang.
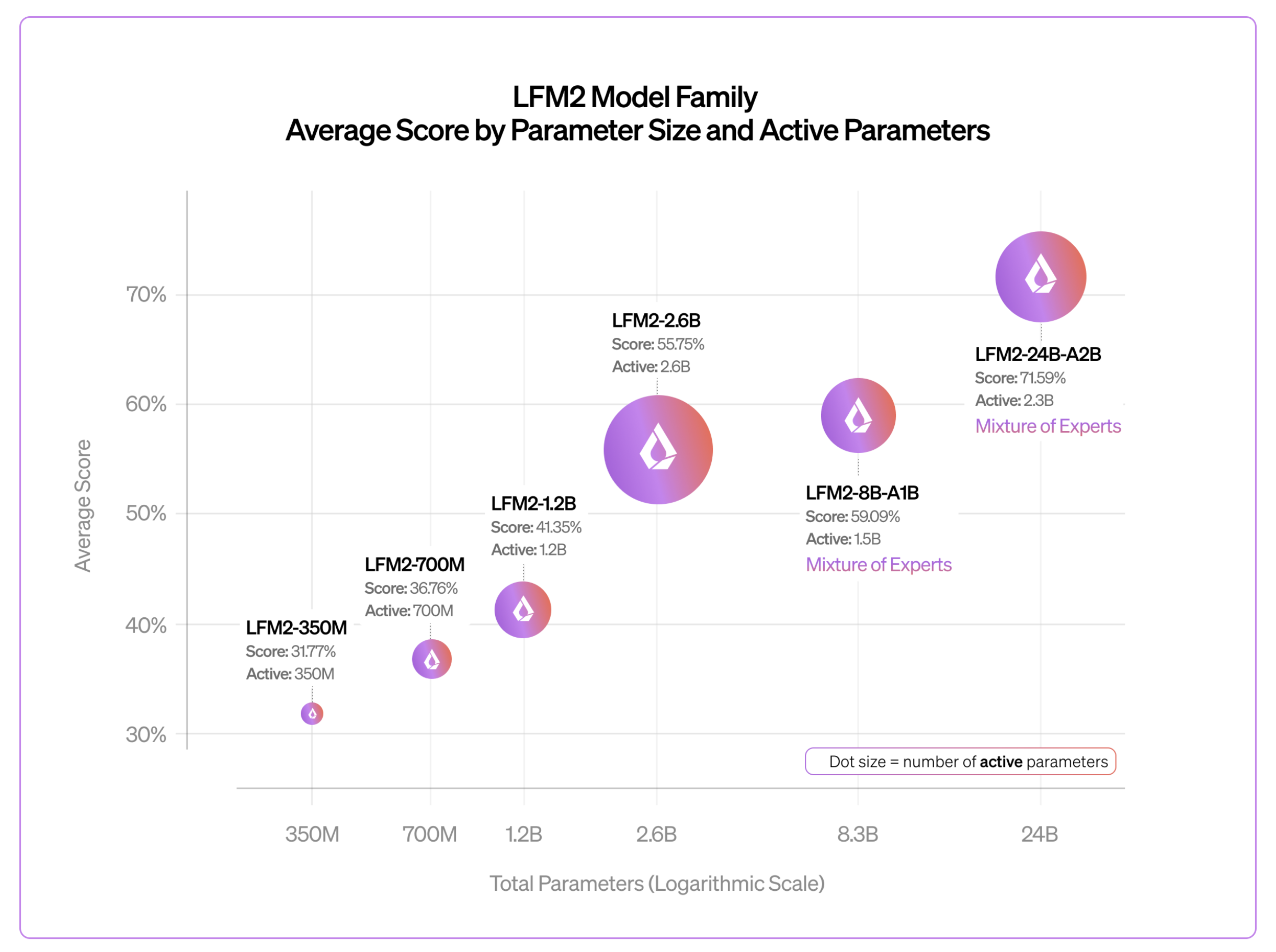
- Predictable scaling: Quality improves log-linearly from 350M to 24B total parameters, confirming the LFM2 hybrid architecture scales reliably across nearly two orders of magnitude.
Model details
LFM2-24B-A2B is a general-purpose instruct model (without reasoning traces) with the following features:
| Property | LFM2-8B-A1B | LFM2-24B-A2B |
|---|---|---|
| Total parameters | 8.3B | 24B |
| Active parameters | 1.5B | 2.3B |
| Layers | 24 (18 conv + 6 attn) | 40 (30 conv + 10 attn) |
| Context length | 32,768 tokens | 32,768 tokens |
| Vocabulary size | 65,536 | 65,536 |
| Training precision | Mixed BF16/FP8 | Mixed BF16/FP8 |
| Training budget | 12 trillion tokens | 17 trillion tokens |
| License | LFM Open License v1.0 | LFM Open License v1.0 |
Supported languages: English, Arabic, Chinese, French, German, Japanese, Korean, Spanish, Portuguese
Generation parameters:
temperature: 0.1top_k: 50repetition_penalty: 1.05
Liquid recommends the following use cases:
- Agentic tool use: Native function calling, web search, structured outputs. Ideal as the fast inner-loop model in multi-step agent pipelines.
- Offline document summarization and Q&A: Run entirely on consumer hardware for privacy-sensitive workflows (legal, medical, corporate).
- Privacy-preserving customer support agent: Deployed on-premise at a company, handles multi-turn support conversations with tool access (database lookups, ticket creation) without data leaving the network.
- Local RAG pipelines: Serve as the generation backbone in retrieval-augmented setups on a single machine without GPU servers.
Architecture
LFM2 is a hybrid architecture that pairs efficient gated short convolution blocks with a small number of grouped query attention (GQA) blocks.
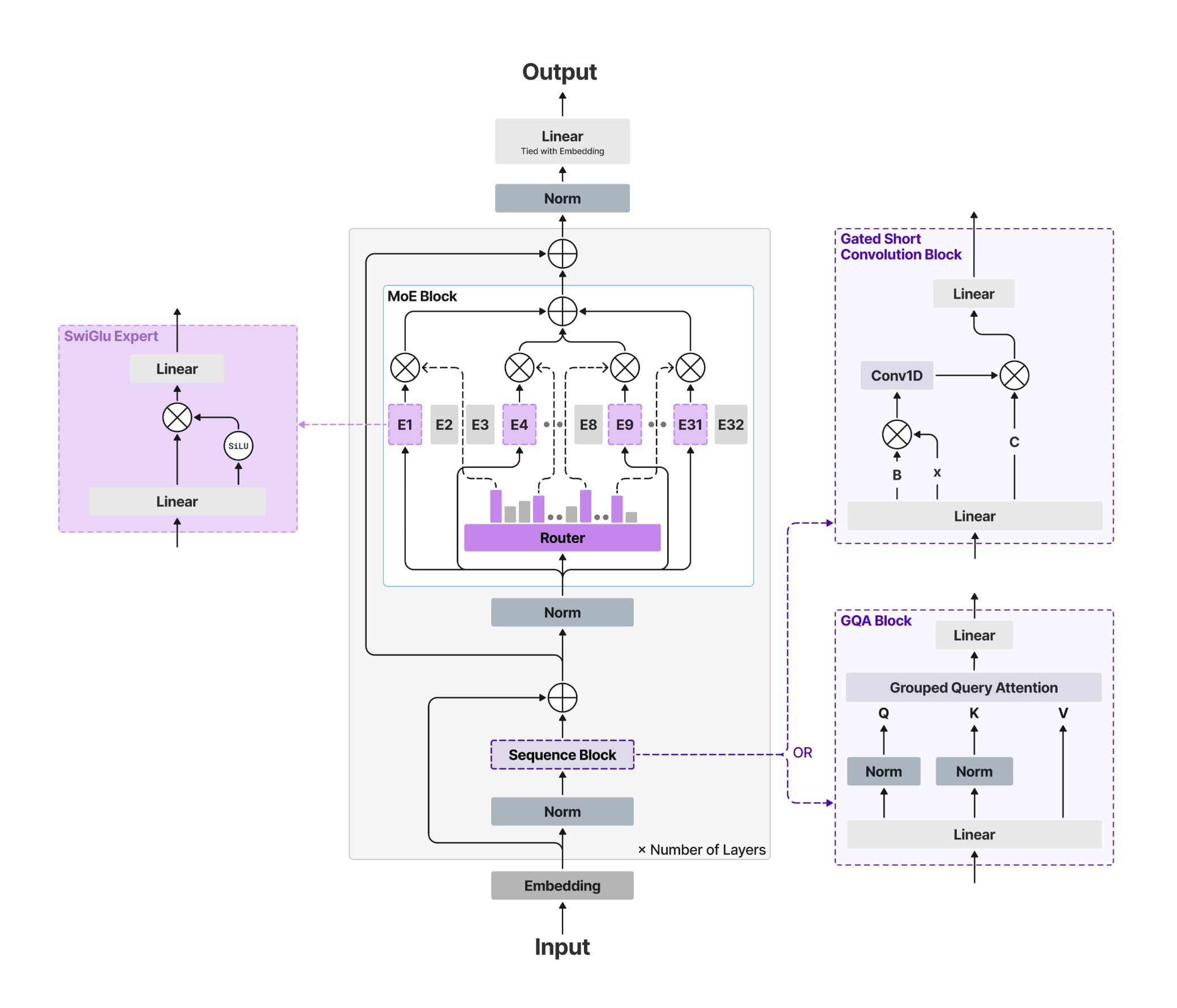
This design, developed through hardware-in-the-loop architecture search, gives LFM2 models fast prefill and decode at low memory cost. LFM2-24B-A2B applies this backbone in a Mixture of Experts configuration: with 24B total parameters but only 2.3B active per forward pass, it punches far above the cost of a 2B dense model at inference time.
Benchmarks
Across benchmarks including GPQA Diamond, MMLU-Pro, IFEval, IFBench, GSM8K, and MATH-500, quality improves log-linearly as we scale from 350M to 24B total parameters. This near-100x parameter range confirms that the LFM2 hybrid architecture follows predictable scaling behavior and does not hit a ceiling at small model sizes.
License
LFM2 is provided under the custom LFM1.0 license.