gpt-oss
gpt-oss
OpenAI's first open source LLM. Comes in 2 sizes: 20B and 120B. Supports configurable reasoning effort (low, medium, high). Trained for tool use. Apache 2.0 licensed.
Memory Requirements
To run the smallest gpt-oss, you need at least 12 GB of RAM. The largest one may require up to 65 GB.
Capabilities
gpt-oss models support tool use and reasoning. They are available in gguf and mlx.
About gpt-oss

The gpt-oss series are OpenAI's open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases. This release includes two models: gpt-oss-120b and gpt-oss-20b.
The gpt-oss-120b model achieves near-parity with OpenAI o4-mini on core reasoning benchmarks, while running efficiently on a single 80 GB GPU. The gpt-oss-20b model delivers similar results to OpenAI o3‑mini on common benchmarks and can run on edge devices with just 16 GB of memory, making it ideal for on-device use cases, local inference, or rapid iteration without costly infrastructure.
Both models were trained using our harmony response format. LM Studio ships with Harmony to support gpt-oss.
OpenAI released a paper alongside these models, available here: https://arxiv.org/abs/2508.10925.
Use with LM Studio's Responses API compatibility mode
LM Studio supports OpenAI's Responses API (docs).
gpt-oss models are expected work best with this API. They and are designed to be used within agentic workflows with exceptional instruction following.
Highlights
- Permissive Apache 2.0 license: Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
- Configurable reasoning effort: Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
- Full chain-of-thought: Provides complete access to the model's reasoning process, facilitating easier debugging and greater trust in outputs. This information is not intended to be shown to end users.
- Fine-tunable: Fully customize models to your specific use case through parameter fine-tuning.
- Agentic capabilities: Use the models' native capabilities for function calling, web browsing, Python code execution, and Structured Outputs.
- MXFP4 quantization: The models were post-trained with MXFP4 quantization of the MoE weights, making
gpt-oss-120brun on a single 80GB GPU (like NVIDIA H100 or AMD MI300X) and thegpt-oss-20bmodel run within 16GB of memory. All evals were performed with the same MXFP4 quantization.
Download the model
Use the lms CLI or download the model within LM Studio.
# gpt-oss-20b lms get openai/gpt-oss-20b # gpt-oss-120b lms get openai/gpt-oss-120b
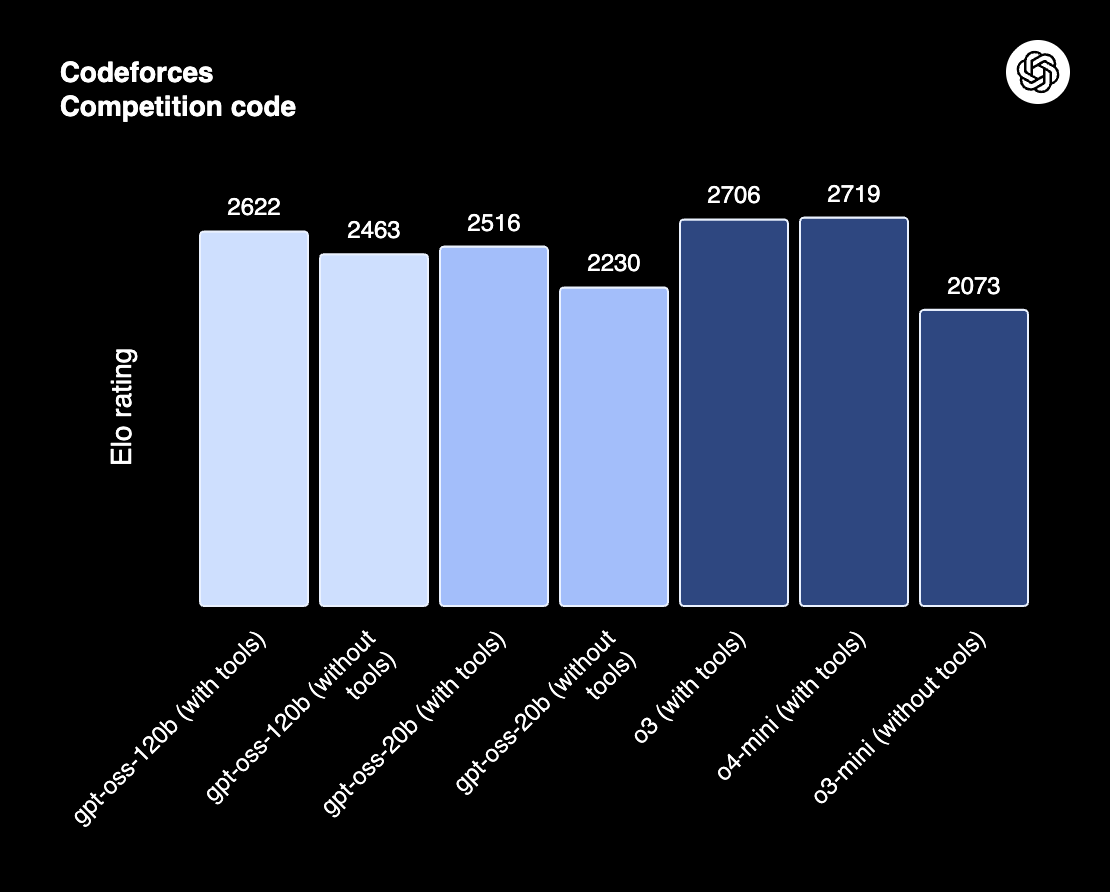
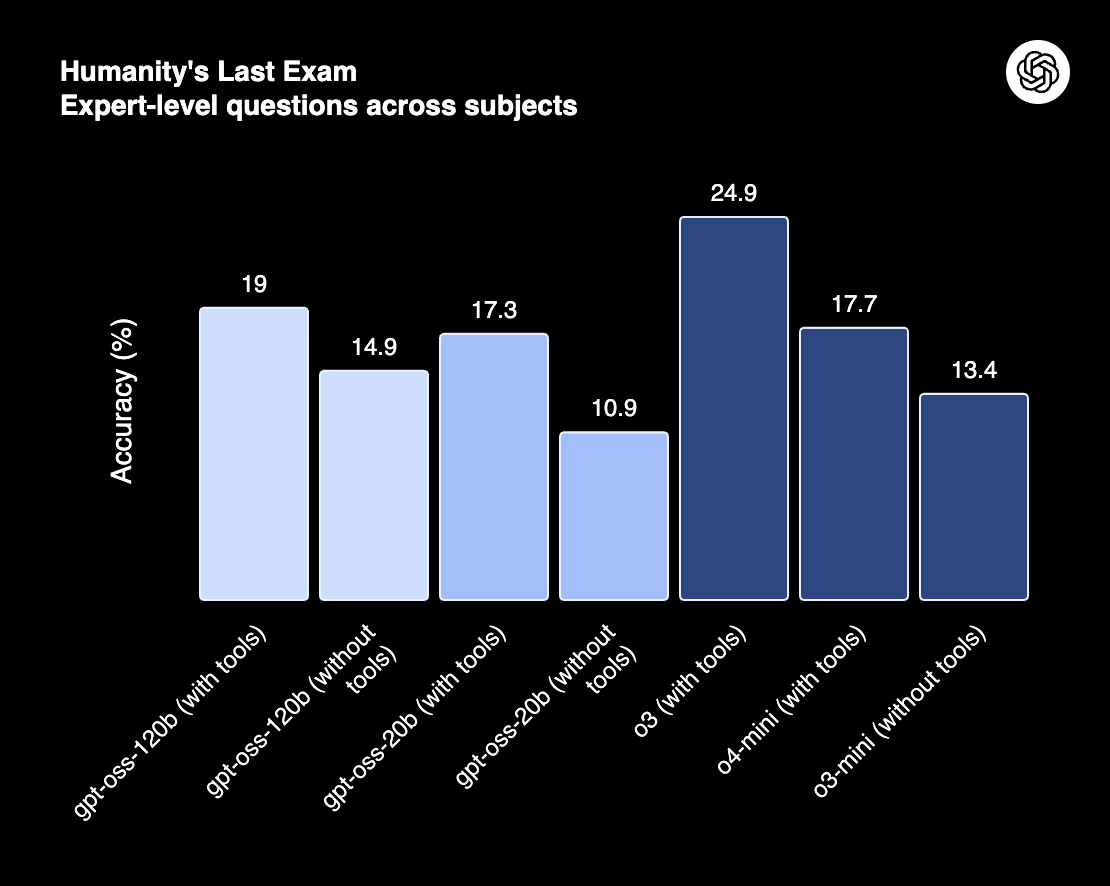
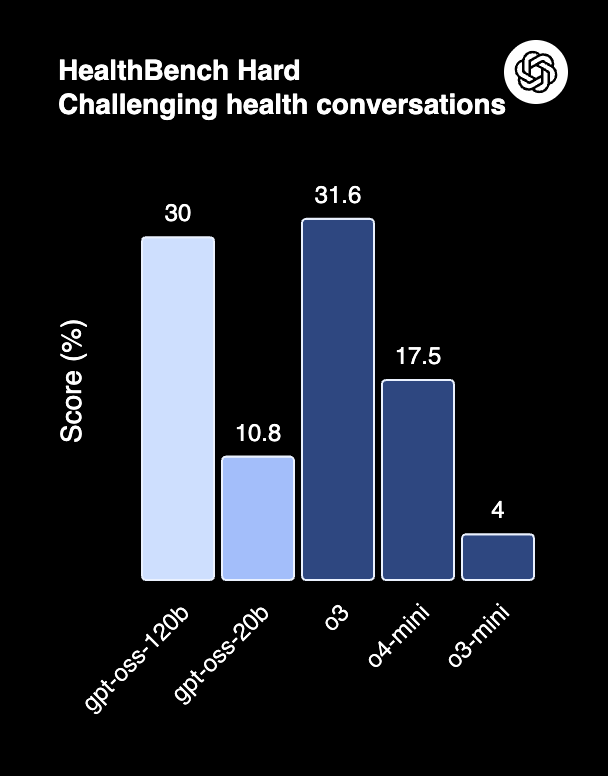
Performance
Select benchmark metrics
License
gpt-oss models are Apache 2.0 licensed.