Introducing the unified multi-modal `MLX` engine architecture in LM Studio

LM Studio's MLX engine (MIT) leverages two powerful Python packages for running LLMs efficiently on Apple Silicon M chips: mlx-lm for text generation (by @awni, @angeloskath, Apple) and mlx-vlm for vision-enabled language models (by @Blaizzy).
Starting with mlx-engine commit f98317e (in-app engine v0.17.0 and up), we migrated to a new unified architecture that weaves together the foundational components of each of those packages. Now mlx-lm's text model implementations are always used, and mlx-vlm's vision model implementations are modularly used as "add-ons" to generate image embeddings that can be understood by the text model.
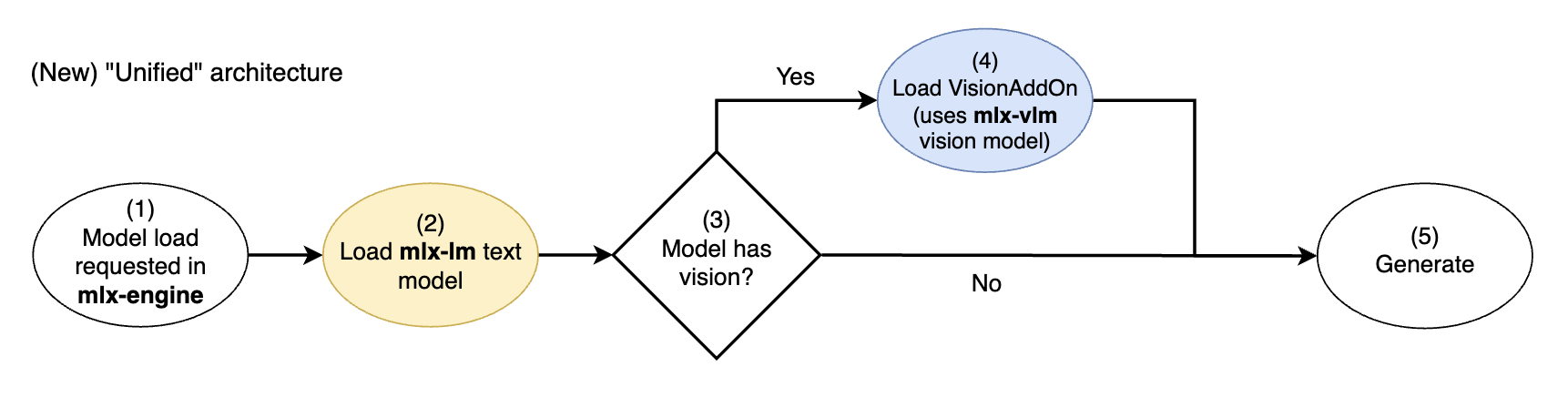
New mlx-engine's unified vision model architecture. mlx-lm text models are extended with mlx-vlm vision add-ons
This massively improves performance and user experience when using multi-modal MLX VLMs (e.g., Google's Gemma 3). For example, text-only chats with VLMs can now benefit from prompt caching — a feature previously exclusive to text-only LLMs — resulting in drastically faster follow-up responses. This makes MLX VLMs seamlessly interchangeable with text-only LLMs for text tasks, while offering vision capabilities as a bonus.
👓 Read on for a technical deepdive into the problem, the solution, and how we achieved this unified architecture in LM Studio's MLX engine.
👷 open source contributions to LM Studio's MLX engine are extremely welcome! If you want to help us extend the unified architecture to more models, see this github issue for a great starting point.
What is a Multi-Modal model?
A multi-modal LLM is an LLM that can take multiple modalities of input. This means that in addition to being able to process text input, the LLM can also accept images and/or audio input.
The new MLX engine does not yet handle audio, but we plan for this approach to work for audio input as well.
Generally, vision-capable LLMs ingest image input through the following flow:
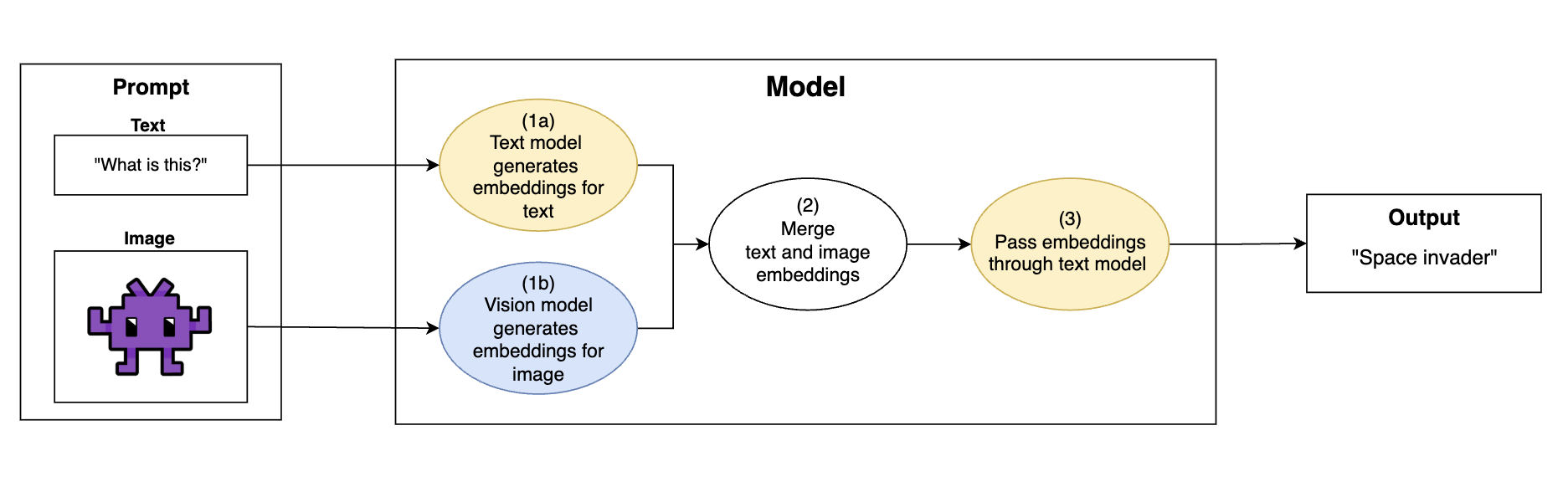
General operational flow of a multi-modal vision LLM: Convert images into embeddings that can be understood by the text model, generate output with the text model
- Prompt comes in with text and images
- (1a) "Text" part of the model encodes text into the embedding space of the model
"What is this?"→[0.83, 0.40, 0.67, ...]
- (1b) "Vision" part of the model encodes images into the embedding space of the text model. This translates the image into a format that the text model can understand
image.png→[0.28, 0.11, 0.96, ...]
- (2) Text and image embeddings are merged together
[0.83, 0.40, 0.67, ...]+[0.28, 0.11, 0.96, ...]→[0.83, 0.40, 0.67, ..., 0.28, 0.11, 0.96, ...]
- (3) Merged embeddings are passed through the text model, and the model generates text based on the information from both the text and images
If there are no images in the prompt, then the "merged embeddings" are simply the text embeddings.
Model Implementations in the MLX Ecosystem
In the MLX Python landscape, there are two major libraries providing model implementations and infrastructure for interacting with LLMs on Apple Silicon:
mlx-lm: text model implementations and infrastructure for interacting with themmlx-vlm: text model implementations, vision model implementations, and infrastructure for interacting with them
Historically, mlx-lm has contained implementations for text-only models without multi-modal functionality, while mlx-vlm is the de-facto home for MLX VLM implementations.
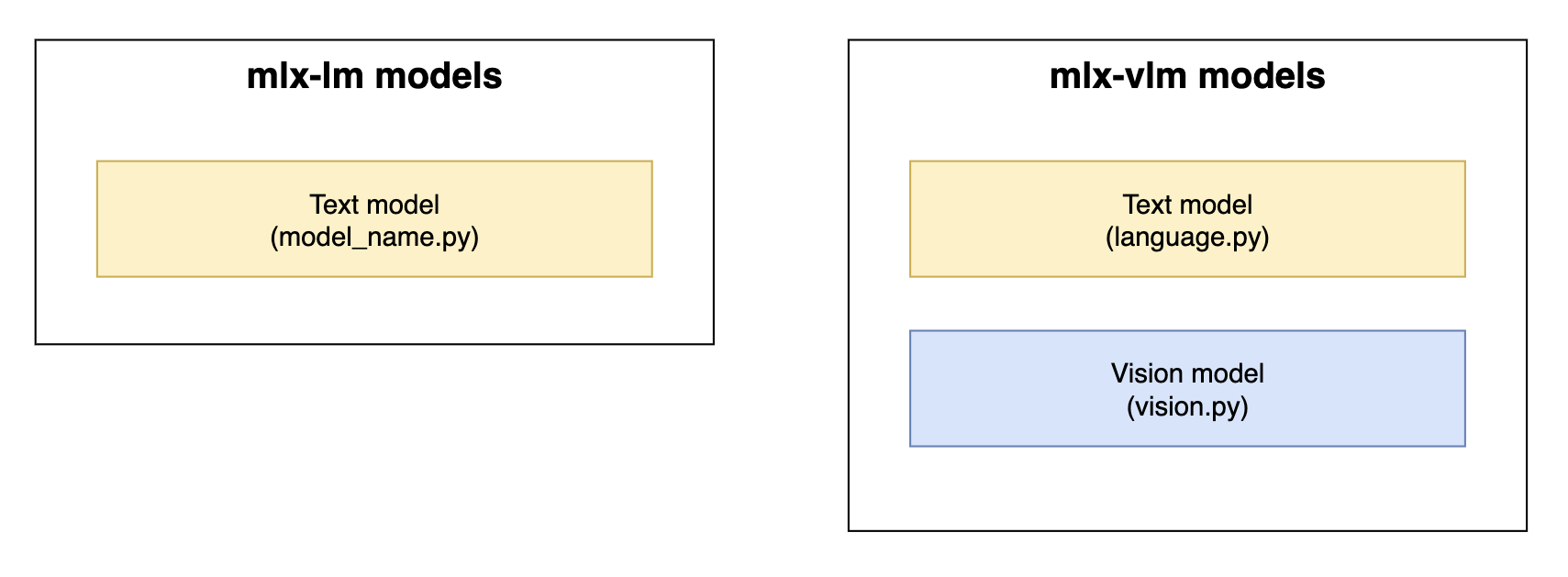
Model implementation components in mlx-lm and mlx-vlm. Yellow = text model components. Blue = vision model components
LM Studio's mlx-engine was originally developed with a simple "forked" architecture to support both text-only models and vision-capable models:
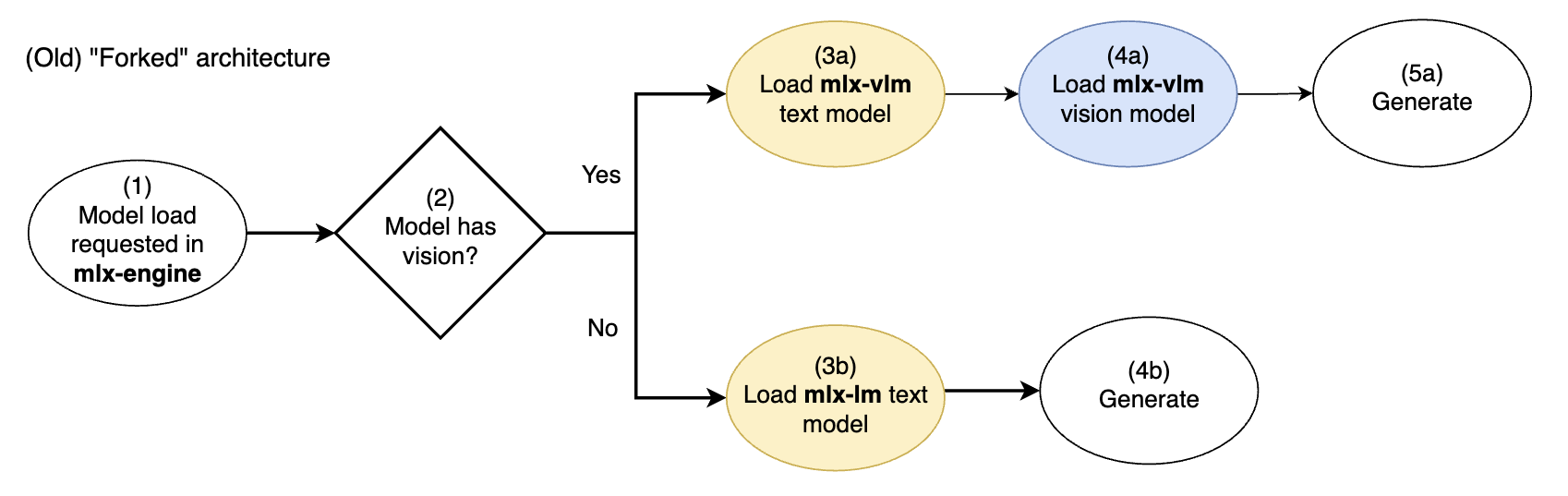
Old mlx-engine's forked vision model architecture. Yellow = text model components. Blue = vision model components
If a model was vision-capable, the mlx-vlm model implementation (text + vision) would be exclusively used. If the model was text-only, the mlx-lm model implementation (text) would be exclusively used.
A distinct (different) text model implementation (from mlx-lm OR from mlx-vlm) was used in each path.
The Problem: Forked Architecture
mlx-engine's naive forked architecture suffered from the following problems:
- When the features of
mlx-lmandmlx-vlmare not perfectly in parity or have nuanced differences in behavior, which one should we use?- How can we limit divergence in the experience interacting with multi-modal models vs. text-only models?
- Suppose one implementation performs better than the other, or contains a bug that the other doesn't. How do we consistently choose whether to use
mlx-lmvs.mlx-vlm? Should we hot-swap loading between them depending on the request (complex)?
- If we do any switching between the two, or support use of text-only variants of multi-modal models (e.g., this Gemma 3 text-only model), then the surface area of bugs and maintenance for a given model is doubled. This is because there are two co-existing implementations that are conditionally used to inference the same underlying model. We therefore have to ensure that two separate models are bug-free to provide a bug-free experience in LM Studio.
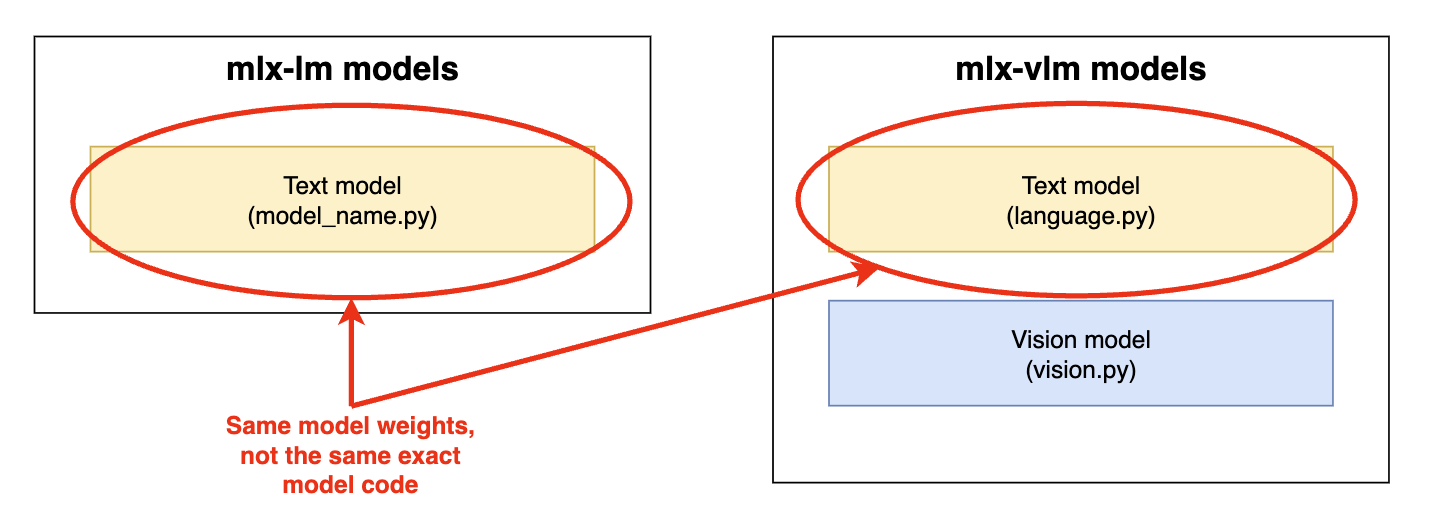
Two separate versions of the same text model exist
Our Solution: Best of Both Worlds
We sought to combine core components of mlx-lm and mlx-vlm to create a "unified" (no forking) inference engine for all MLX LLMs and VLMs.
After invaluable discussion with @awni and @Blaizzy, we enabled this through the following contributions:
mlx-lm
mlx-vlm
- Gemma3 and Qwen2.5VL text-image input merging functions public
mlx-vlm#335 - Pixtral merge_input_ids function public static
mlx-vlm#355
New mlx-engine's unified vision model architecture. mlx-lm text models are extended with mlx-vlm vision add-ons
In this unified architecture, always load the core text model of a multi-modal LLM from mlx-lm (2), no longer potentially loading a slightly different text model from mlx-vlm.
We then conditionally load a VisionAddOn that uses mlx-vlm functionality (3,4) to generate embeddings from images that the mlx-lm text model can understand (see the Gemma3VisionAddOn implementation in mlx-engine).
With this setup, we are able to inference multi-modal models in a streamlined and single-path fashion. This helps us release cleaner, more maintainable LM Studio MLX engines with improved performance.
Gemma 3 12B QAT, both MLX 4 bit on M3 MacBook Pro. ~25x faster follow-up TTFT with the unified architecture
Details: VisionAddOns in mlx-engine
The gist of LM Studio's new mlx-engine unified architecture is that it allows us to use the text model implementations from mlx-lm for all multi-modal models, while still being able to leverage the vision model components from mlx-vlm to generate image embeddings that can be understood by the text model.
This is achieved by introducing VisionAddOns (source), which are modular components that can be used to generate image embeddings for multi-modal models. These VisionAddOns implement a common interface defined by the BaseVisionAddOn abstract class, for example:
class BaseVisionAddOn:
"""
Base class that defines the interface for a VisionAddOn.
"""
@abstractmethod
def __init__(self):
"""
Where load of vision model components is intended to occur.
"""
@abstractmethod
def compute_embeddings(
self,
text_model: nn.Module,
prompt_tokens: mx.array,
images_b64: List[str],
) -> mx.array:
"""
Returns input embeddings for the language model after
text/image merging of the prompt
"""VisionAddOns generate image embeddings that can be input into a new input_embeddings argument of mlx-lm's stream_generate() function (see commit made to mlx-lm).
Right now, Gemma 3 (Gemma3VisionAddOn) and Pixtral (PixtralVisionAddOn) are the only two models that have been migrated to the unified architecture. However, the architecture is designed such that more VisionAddOns can be easily added to mlx-engine's vision_add_ons directory, then wired into the ModelKit here:
VISION_ADD_ON_MAP = {
"gemma3": Gemma3VisionAddOn,
"pixtral": PixtralVisionAddOn,
}Contributions to extend this pattern in our open source repo https://github.com/lmstudio-ai/mlx-engine are extremely welcome!
For example, see mlx-engine issue Extend VisionAddOn Pattern to Qwen2.5VL #167.
Feedback and Contributions
- See and/or contribute to our open-source
mlx-enginerepo at https://github.com/lmstudio-ai/mlx-engine - Download the latest LM Studio from https://lmstudio.ai/download.
- New to LM Studio? Head over to the documentation: Getting Started with LM Studio.
- For discussions and community, join our Discord server: https://discord.gg/aPQfnNkxGC
- If you want to use LM Studio at your organization at work, get in touch: LM Studio @ Work