OpenAI gpt-oss-safeguard
LM Studio partnered with OpenAI to support gpt-oss-safeguard: open, safety‑focused reasoning models (120B and 20B) that follow custom policies you provide.
These models accept a developer‑provided policy at inference time, reason over new input against that policy, and produce a response (including explanations) aligned to your definitions.
Run gpt-oss-safeguard locally
Download either the 20B or 120B variant into LM Studio using the GUI or the lms CLI:
lms get openai/gpt-oss-safeguard-20blms get openai/gpt-oss-safeguard-120bThen use LM Studio’s SDK or the OpenAI Responses API compatibility mode to call the model from your code.
How gpt-oss-safeguard uses policy prompts
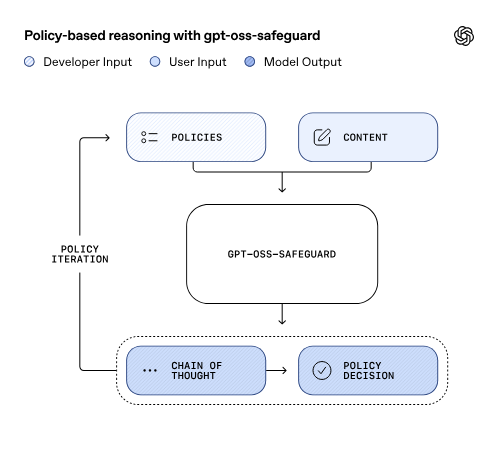
gpt-oss-safeguard uses your written policy as governing logic. Where typical models return confidence scores tied to training data (and often require retraining to change behavior), gpt-oss-safeguard reasons within the boundaries of your taxonomy. This lets Trust & Safety teams plug it in as a policy‑aligned reasoning layer inside existing moderation or compliance systems, and iterate on policies instantly without retraining.
Example policy prompt template
Copy this template and customize it in a new named Preset
## Policy Definitions
### Key Terms
**[Term 1]**: [Definition]
**[Term 2]**: [Definition]
**[Term 3]**: [Definition]
## Content Classification Rules
### VIOLATES Policy (Label: 1)
Content that:
- [Violation 1]
- [Violation 2]
- [Violation 3]
- [Violation 4]
- [Violation 5]
### DOES NOT Violate Policy (Label: 0)
Content that is:
- [Acceptable 1]
- [Acceptable 2]
- [Acceptable 3]
- [Acceptable 4]
- [Acceptable 5]
## Examples
### Example 1 (Label: 1)
**Content**: "[Example]"
**Expected Response**:
### Example 2 (Label: 1)
**Content**: "[Example]"
**Expected Response**:
### Example 3 (Label: 0)
**Content**: "[Example]"
**Expected Response**:
### Example 4 (Label: 0)
**Content**: "[Example]"
**Expected Response**:License
gpt-oss-safeguard models are provided under the Apache-2.0 license.
Learn more
Learn more about this model in OpenAI's blog post: Introducing gpt-oss-safeguard.