← All Models

Qwen3 Next
53.8K Downloads
Qwen3 Next
53.8K Downloads
Hybrid attention architecture, high-sparsity Mixture-of-Experts 80B model (active 3B).
Models
Updated 7 months ago
42.00 GB
Memory Requirements
To run the smallest Qwen3 Next, you need at least 42 GB of RAM.
Capabilities
Qwen3 Next models support tool use. They are available in gguf and mlx.
About Qwen3 Next
The first model in the Qwen3-Next series featuring innovative hybrid attention architecture and high-efficiency Mixture-of-Experts design.
Key Features
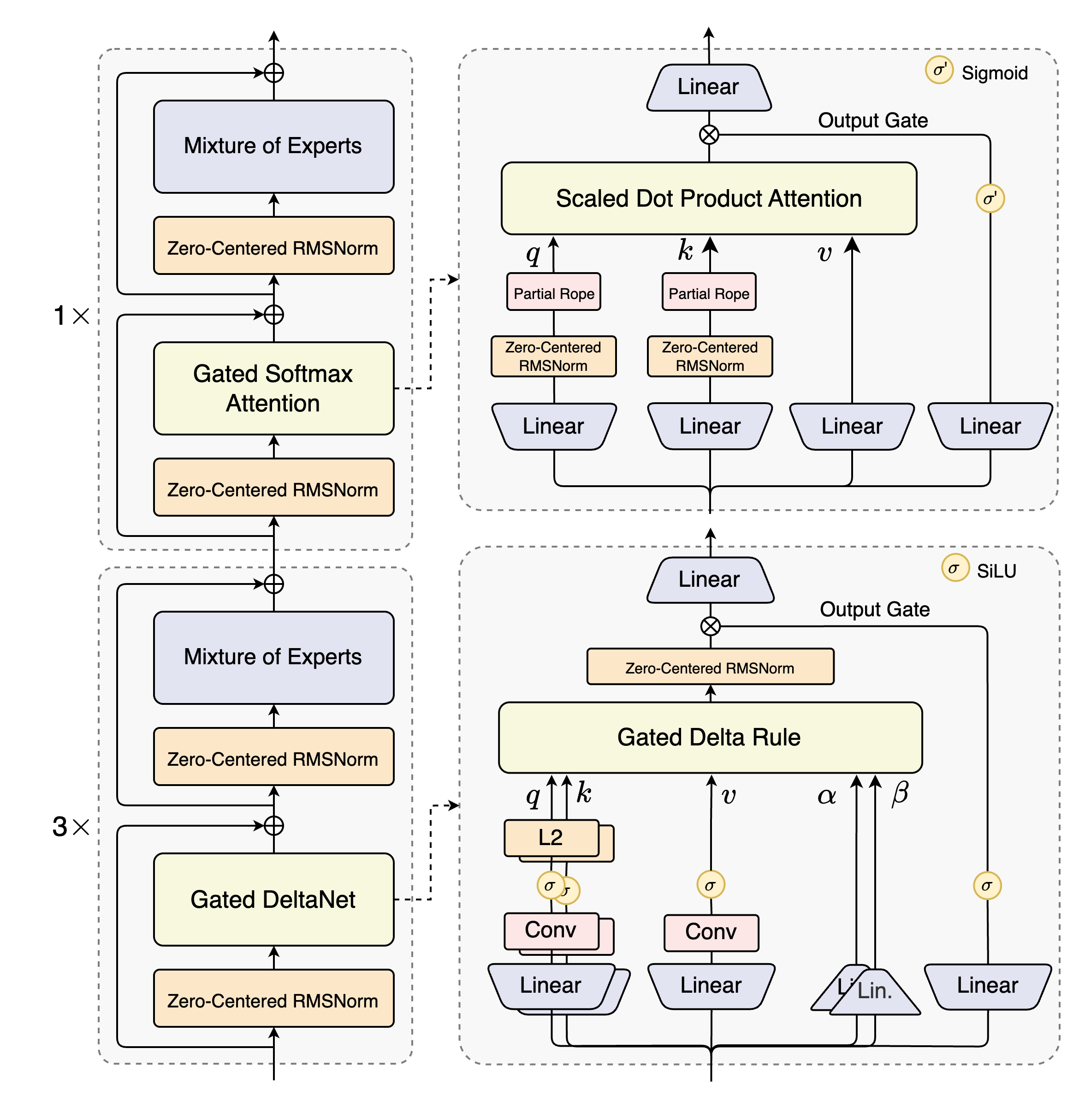
- Hybrid Attention: Combines Gated DeltaNet and Gated Attention for efficient ultra-long context modeling
- High-Sparsity MoE: 80B total parameters with only 3B activated, providing excellent efficiency
- Ultra-Long Context: Supports up to 262,144 tokens natively
- Multi-Token Prediction: Enhanced pretraining performance and faster inference
- Advanced Capabilities: Excels at reasoning, coding, creative writing, and agentic tasks
- Multilingual Support: Over 100 languages and dialects
Architecture Highlights
- 80B total parameters, 3B activated (A3B)
- 48 layers with hybrid layout
- 512 experts with only 10 activated per token
- Context length: 262,144 tokens
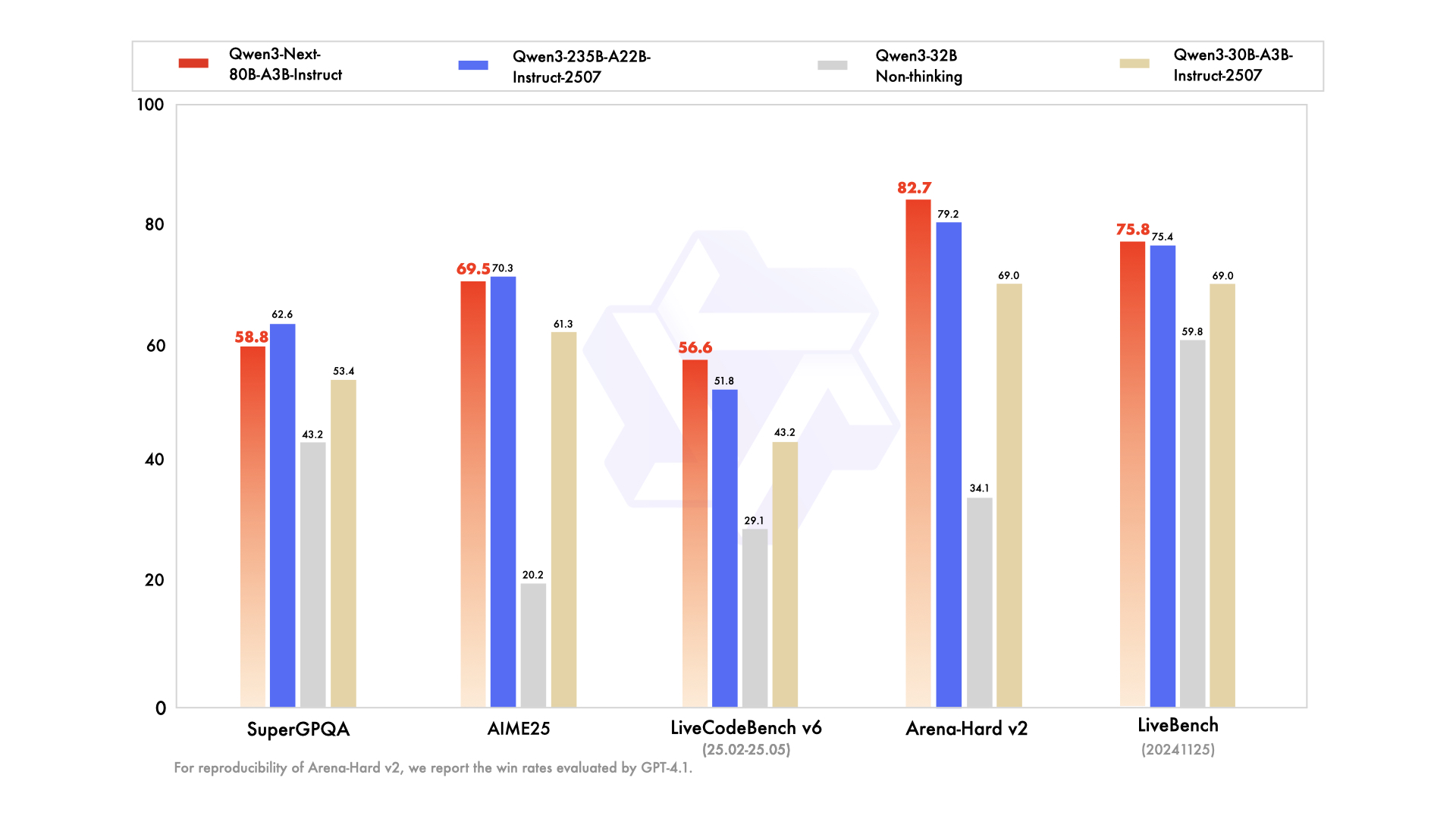
Performance
Delivers performance comparable to much larger models while maintaining exceptional efficiency:
- Outperforms Qwen3-32B with 10x inference throughput for long contexts
- Matches Qwen3-235B-A22B on many benchmarks with significantly lower computational requirements
- Superior ultra-long-context handling up to 256K+ tokens
Architecture
Details:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Hidden Dimension: 2048
- Number of Layers: 48
- Hybrid Layout: 12 * (3 * (Gated DeltaNet → MoE) → 1 * (Gated Attention → MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens