Qwen3 (1st Generation)
Qwen3 (1st Generation)
The first batch of Qwen3 models (Qwen3-2504), a collection of dense and MoE models ranging from 4B to 235B. These are general purpose models that score highly on benchmarks.
Memory Requirements
To run the smallest Qwen3 (1st Generation), you need at least 2 GB of RAM. The largest one may require up to 134 GB.
Capabilities
Qwen3 (1st Generation) models support tool use and reasoning. They are available in gguf and mlx.
About Qwen3 (1st Generation)
There's a new Qwen3 batch! Head to Qwen3. This page documents the first Qwen3 batch from April 2025.

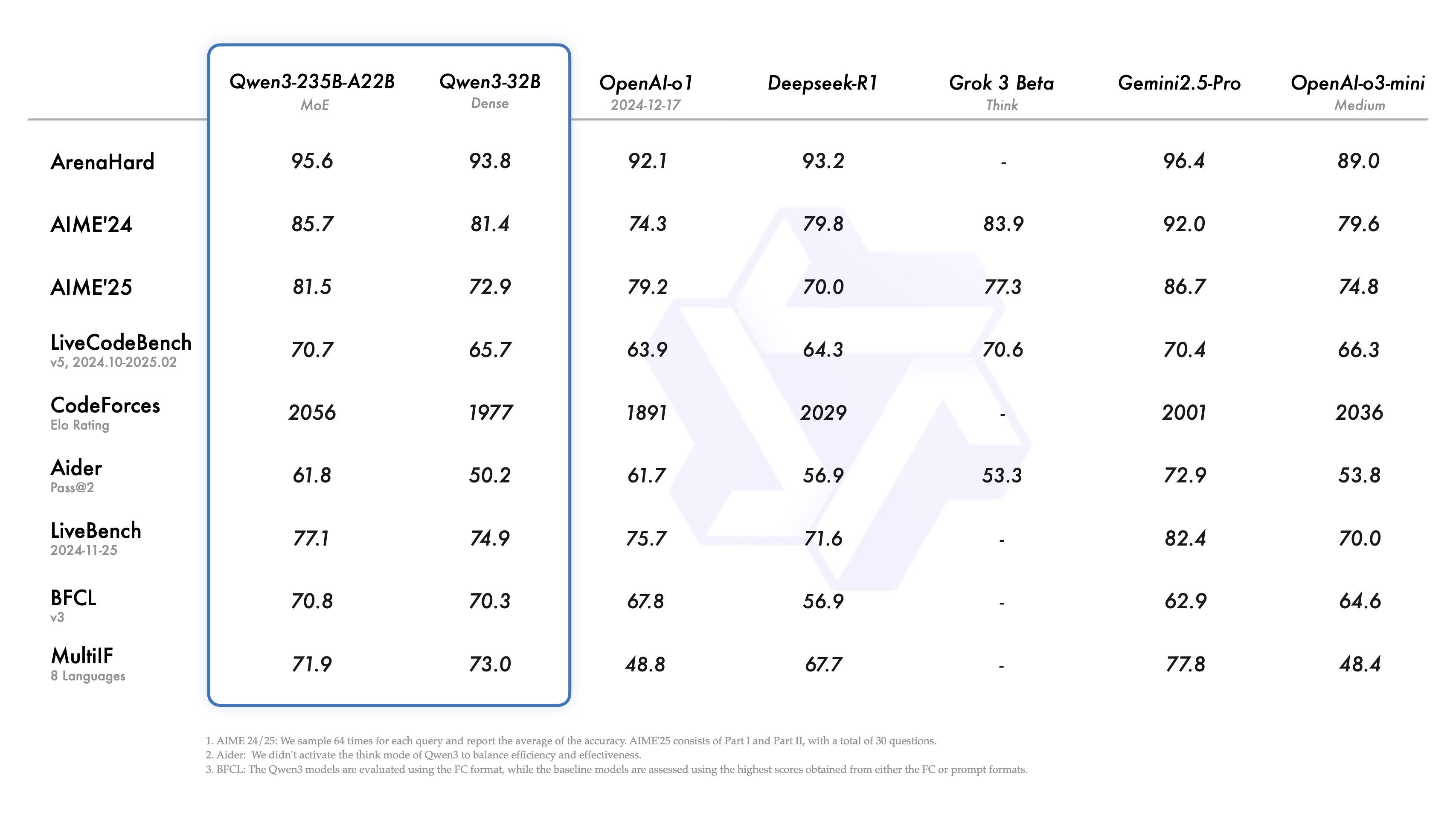
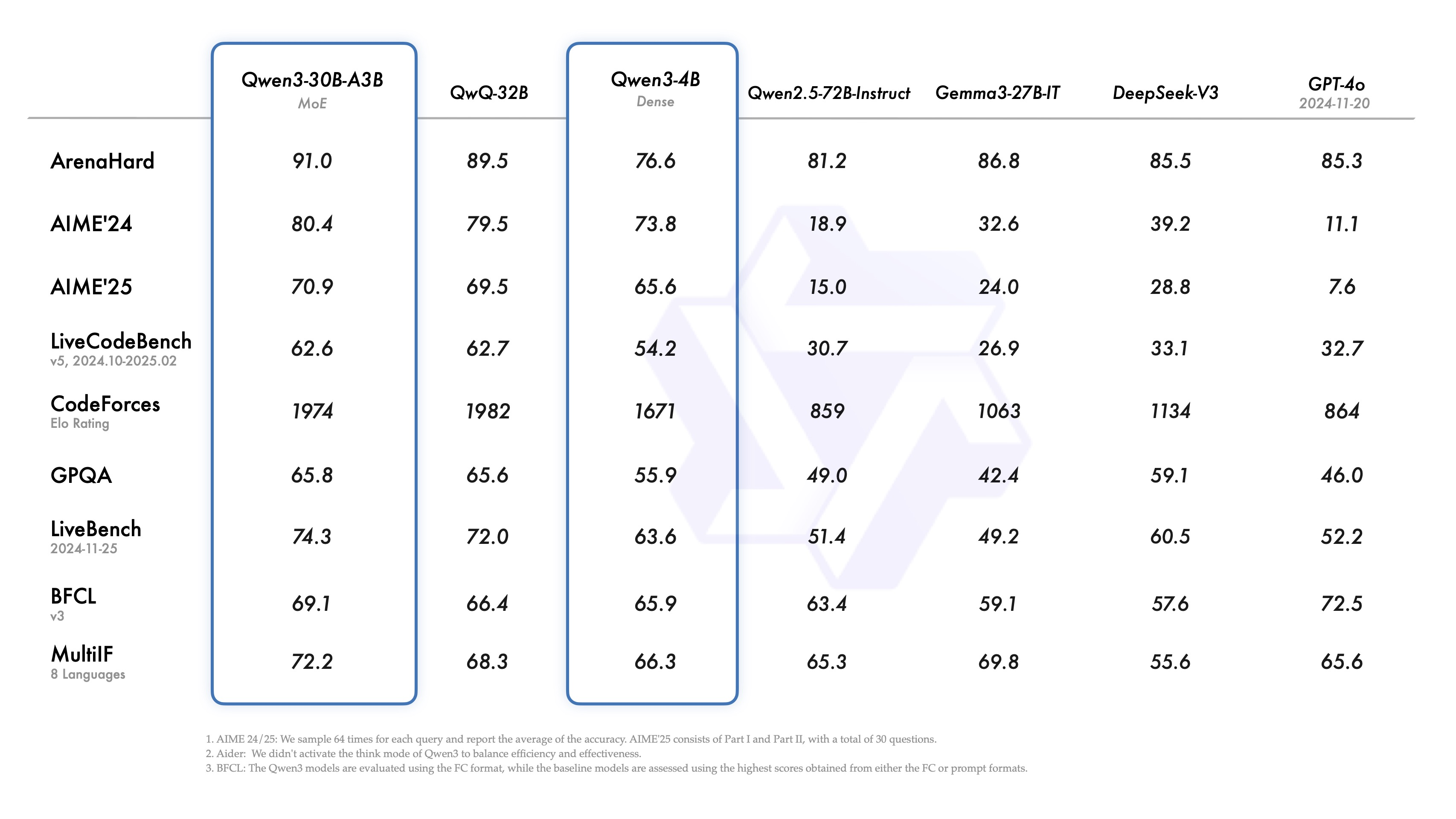
As a part of the Qwen3 release, Alibaba shared two MoE models: Qwen3-235B-A22B, a large model with 235 billion total parameters and 22 billion activated parameters, and Qwen3-30B-A3B, a smaller MoE model with 30 billion total parameters and 3 billion activated parameters. Additionally, six dense models are also open-weighted, including Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B, under Apache 2.0 license.
Key Features
Hybrid Thinking Modes
Qwen3 models introduce a hybrid approach to problem-solving. They support two modes:
-
Thinking Mode: In this mode, the model takes time to reason step by step before delivering the final answer. This is ideal for complex problems that require deeper thought.
-
Non-Thinking Mode: Here, the model provides quick, near-instant responses, suitable for simpler questions where speed is more important than depth.
You can control this mode in LM Studio by toggling the Think button in the chat input box.
Turn thinking on or off in LM Studio
Multilingual Support
Qwen3 models support 119 languages and dialects. This extensive multilingual capability opens up new possibilities for international applications, enabling users worldwide to benefit from the power of these models.
Benchmark performance
License
Qwen3 models are available under the Apache 2.0 license.