qwen2.5-vl
qwen2.5-vl
Qwen2.5-VL is a performant vision-language model, capable of recognizing common objects and text. Supports context length of 128k tokens in a variety of human languages.
Memory Requirements
To run the smallest qwen2.5-vl, you need at least 2 GB of RAM. The largest one may require up to 47 GB.
Capabilities
qwen2.5-vl models support vision input. They are available in gguf.
About qwen2.5-vl

Qwen2.5-VL is a vision-language model that supports context length of 128k tokens.
It is proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
Capable of acting as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
Useful for generating structured outputs and stable JSON outputs.
Key Enhancements over Qwen2-VL:
-
Understand things visually: Qwen2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
-
Being agentic: Qwen2.5-VL directly plays as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
-
Understanding long videos and capturing events: Qwen2.5-VL can comprehend videos of over 1 hour, and this time it has a new ability of cpaturing event by pinpointing the relevant video segments.
-
Capable of visual localization in different formats: Qwen2.5-VL can accurately localize objects in an image by generating bounding boxes or points, and it can provide stable JSON outputs for coordinates and attributes.
-
Generating structured outputs: for data like scans of invoices, forms, tables, etc. Qwen2.5-VL supports structured outputs of their contents, benefiting usages in finance, commerce, etc.
Model architecture
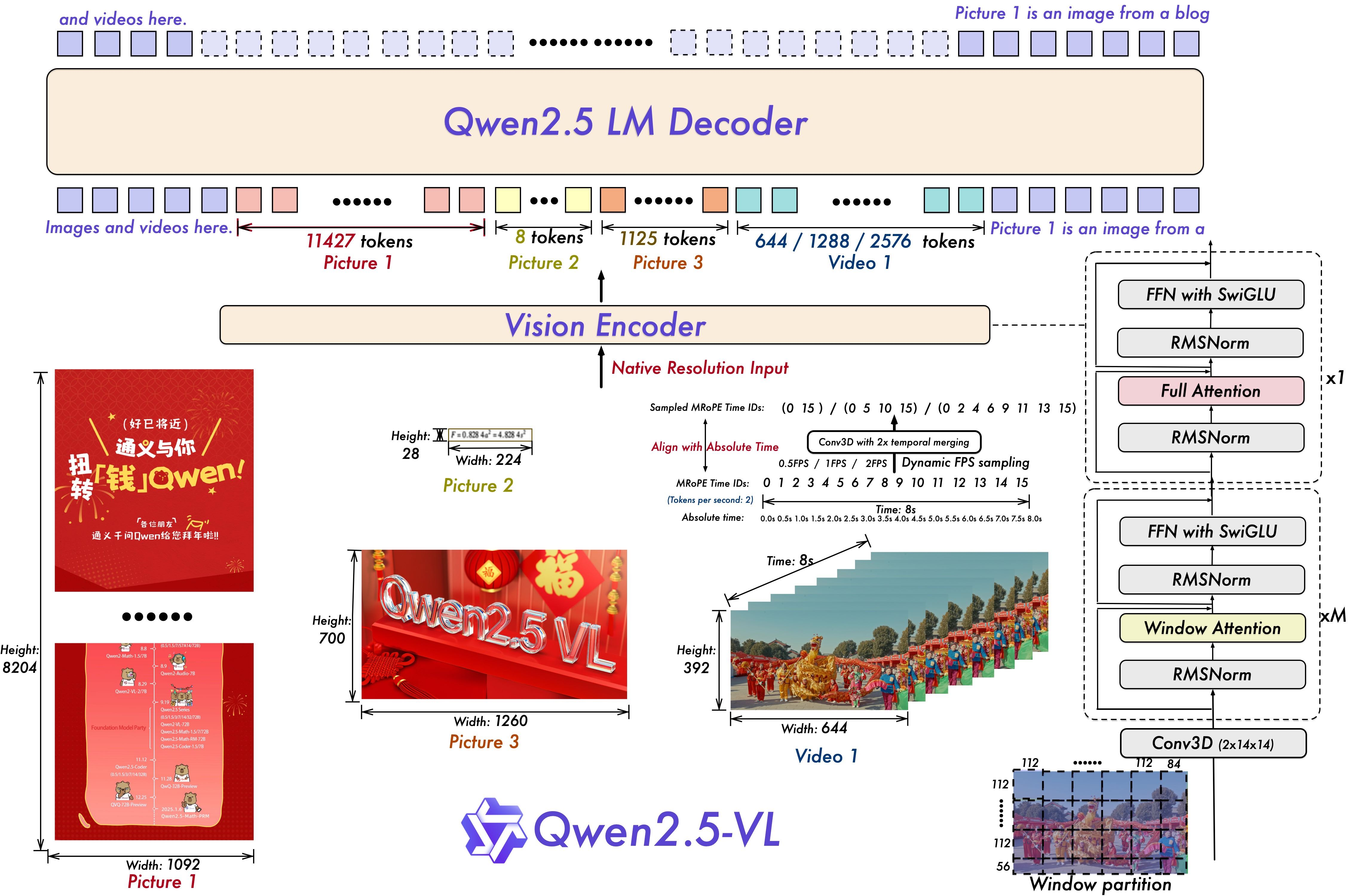
Performance
Image benchmark
| Benchmark | InternVL2.5-8B | MiniCPM-o 2.6 | GPT-4o-mini | Qwen2-VL-7B | Qwen2.5-VL-7B |
|---|---|---|---|---|---|
| MMMUval | 56 | 50.4 | 60 | 54.1 | 58.6 |
| MMMU-Proval | 34.3 | - | 37.6 | 30.5 | 41.0 |
| DocVQAtest | 93 | 93 | - | 94.5 | 95.7 |
| InfoVQAtest | 77.6 | - | - | 76.5 | 82.6 |
| ChartQAtest | 84.8 | - | - | 83.0 | 87.3 |
| TextVQAval | 79.1 | 80.1 | - | 84.3 | 84.9 |
| OCRBench | 822 | 852 | 785 | 845 | 864 |
| CC_OCR | 57.7 | 61.6 | 77.8 | ||
| MMStar | 62.8 | 60.7 | 63.9 | ||
| MMBench-V1.1-Entest | 79.4 | 78.0 | 76.0 | 80.7 | 82.6 |
| MMT-Benchtest | - | - | - | 63.7 | 63.6 |
| MMStar | 61.5 | 57.5 | 54.8 | 60.7 | 63.9 |
| MMVetGPT-4-Turbo | 54.2 | 60.0 | 66.9 | 62.0 | 67.1 |
| HallBenchavg | 45.2 | 48.1 | 46.1 | 50.6 | 52.9 |
| MathVistatestmini | 58.3 | 60.6 | 52.4 | 58.2 | 68.2 |
| MathVision | - | - | - | 16.3 | 25.07 |
Agent benchmark
| Benchmarks | Qwen2.5-VL-7B |
|---|---|
| ScreenSpot | 84.7 |
| ScreenSpot Pro | 29.0 |
| AITZ_EM | 81.9 |
| Android Control High_EM | 60.1 |
| Android Control Low_EM | 93.7 |
| AndroidWorld_SR | 25.5 |
| MobileMiniWob++_SR | 91.4 |