phi-4
phi-4
phi-4 is a state-of-the-art open model built upon a blend of synthetic datasets, data from filtered public domain websites, and acquired academic books and Q&A datasets.
Memory Requirements
To run the smallest phi-4, you need at least 2 GB of RAM. The largest one may require up to 8 GB.
Capabilities
phi-4 models are available in gguf formats.
About phi-4
phi-4 is a state-of-the-art open model built upon a blend of synthetic datasets, data from filtered public domain websites, and acquired academic books and Q&A datasets. The goal of this approach was to ensure that small capable models were trained with data focused on high quality and advanced reasoning.
phi-4 underwent a rigorous enhancement and alignment process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures.
Technical report: https://arxiv.org/pdf/2412.08905
Primary usecase
Phi-4 is designed to accelerate research on language models, for use as a building block for generative AI powered features. It provides uses for general purpose AI systems and applications (primarily in English) which require:
- Memory/compute constrained environments.
- Latency bound scenarios.
- Reasoning and logic.
Performance
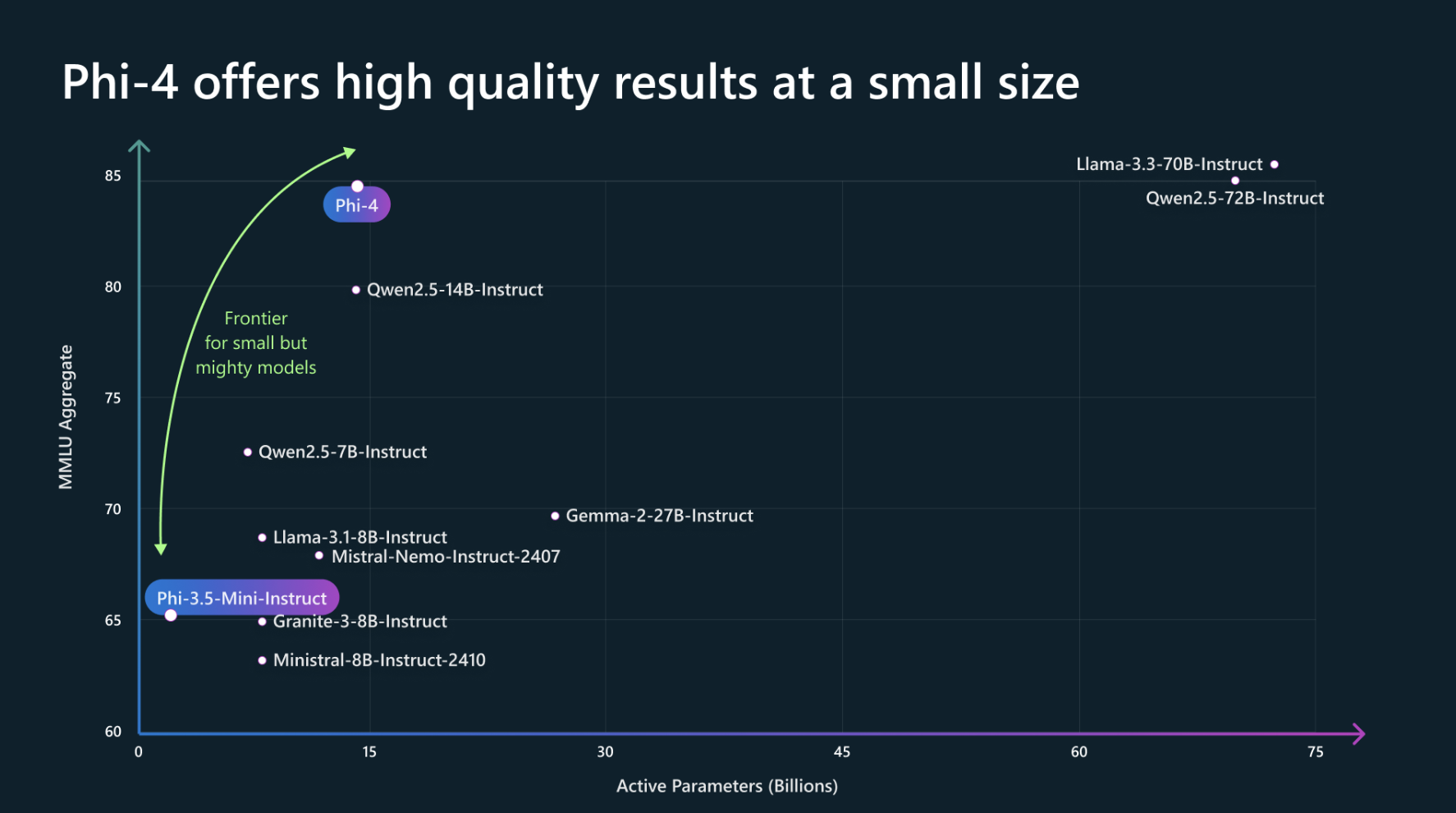
To understand the capabilities, Microsoft compares phi-4 with a set of models over OpenAI’s SimpleEval benchmark.
At the high-level overview of the model quality on representative benchmarks. For the table below, higher numbers indicate better performance:
| Category | Benchmark | phi-4 (14B) | phi-3 (14B) | Qwen 2.5 (14B instruct) | GPT-4o-mini | Llama-3.3 (70B instruct) | Qwen 2.5 (72B instruct) | GPT-4o |
|---|---|---|---|---|---|---|---|---|
| Popular Aggregated Benchmark | MMLU | 84.8 | 77.9 | 79.9 | 81.8 | 86.3 | 85.3 | 88.1 |
| Science | GPQA | 56.1 | 31.2 | 42.9 | 40.9 | 49.1 | 49.0 | 50.6 |
| Math | MGSM MATH | 80.6 80.4 | 53.5 44.6 | 79.6 75.6 | 86.5 73.0 | 89.1 66.3* | 87.3 80.0 | 90.4 74.6 |
| Code Generation | HumanEval | 82.6 | 67.8 | 72.1 | 86.2 | 78.9* | 80.4 | 90.6 |
| Factual Knowledge | SimpleQA | 3.0 | 7.6 | 5.4 | 9.9 | 20.9 | 10.2 | 39.4 |
| Reasoning | DROP | 75.5 | 68.3 | 85.5 | 79.3 | 90.2 | 76.7 | 80.9 |
* These scores are lower than those reported by Meta, perhaps because simple-evals has a strict formatting requirement that Llama models have particular trouble following. Microsoft uses the simple-evals framework because it is reproducible, but Meta reports 77 for MATH and 88 for HumanEval on Llama-3.3-70B.
License
Phi-4 is provided under the MIT license.