mistral-nemo
mistral-nemo
General purpose dense transformer designed for multilingual use cases. Built in collaboration between MistralAI and NVIDIA.
Memory Requirements
To run the smallest mistral-nemo, you need at least 7 GB of RAM.
Capabilities
mistral-nemo models are available in gguf formats.
About mistral-nemo

Mistral NeMo is a 12B model built in collaboration between MistralAI and NVIDIA. Mistral NeMo offers a large context window of up to 128k tokens. Its reasoning, world knowledge, and coding accuracy are state-of-the-art in its size category. As it relies on standard architecture, Mistral NeMo is easy to use and a drop-in replacement in any system using Mistral 7B.
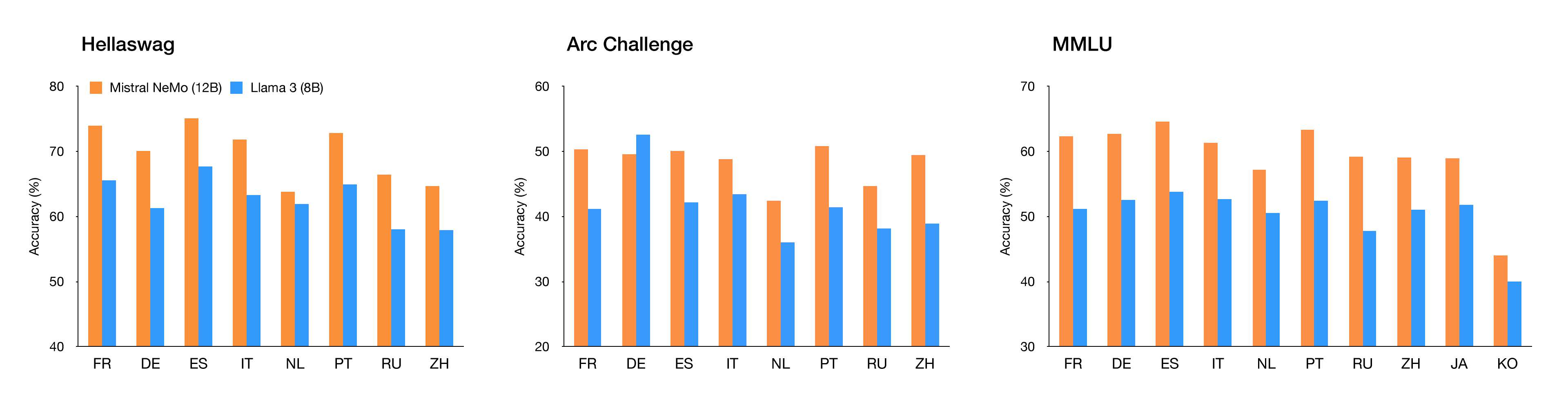
Multilingual usecase
Mistral NeMo is designed for global, multilingual applications. It is trained on function calling, has a large context window, and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. This is a new step toward bringing frontier AI models to everyone’s hands in all languages that form human culture.
Performance
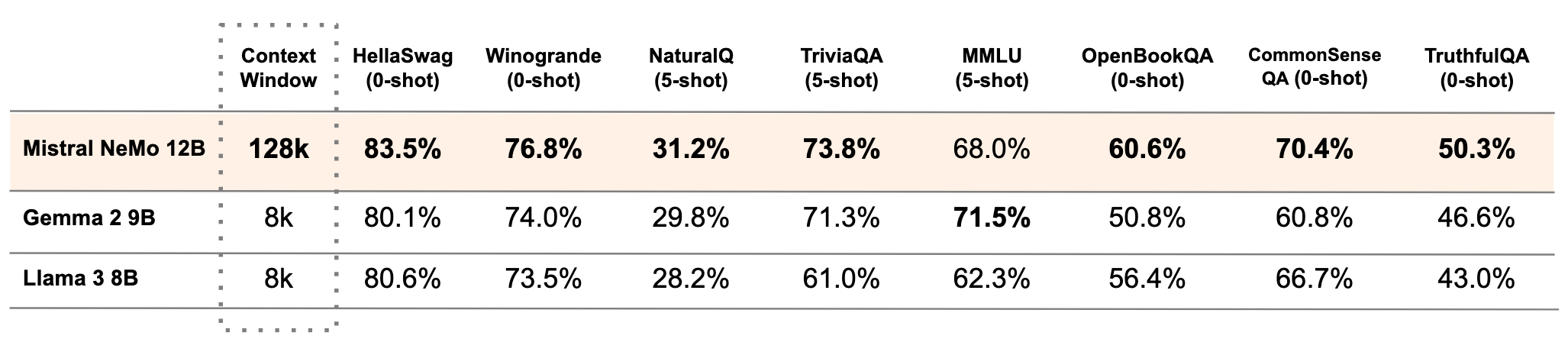
The following table compares the accuracy of the Mistral NeMo base model with two recent open-source pre-trained models, Gemma 2 9B, and Llama 3 8B.
License
Mistral NeMo is provided under the Apache 2.0 license.