deepseek-r1
deepseek-r1
Distilled version of the DeepSeek-R1-0528 model, created by continuing the post-training process on the Qwen3 8B Base model using Chain-of-Thought (CoT) from DeepSeek-R1-0528.
Memory Requirements
To run the smallest deepseek-r1, you need at least 4 GB of RAM. The largest one may require up to 40 GB.
Capabilities
deepseek-r1 models support tool use and reasoning. They are available in gguf and mlx.
About deepseek-r1

These are distilled versions of the DeepSeek-R1-0528 model, created by continuing the post-training process on smaller Qwen3 and Llama base model using Chain-of-Thought (CoT) from DeepSeek-R1-0528.
The DeepSeek R1 model is designed to achieve state-of-the-art performance on reasoning tasks while being more efficient than larger models.
On this model, they say:
we distilled the chain-of-thought from DeepSeek-R1-0528 to post-train Qwen3 8B Base, obtaining DeepSeek-R1-0528-Qwen3-8B. This model achieves state-of-the-art (SOTA) performance among open-source models on the AIME 2024, surpassing Qwen3 8B by +10.0% and matching the performance of Qwen3-235B-thinking. We believe that the chain-of-thought from DeepSeek-R1-0528 will hold significant importance for both academic research on reasoning models and industrial development focused on small-scale models.
DeepSeek-R1-0528 Overview
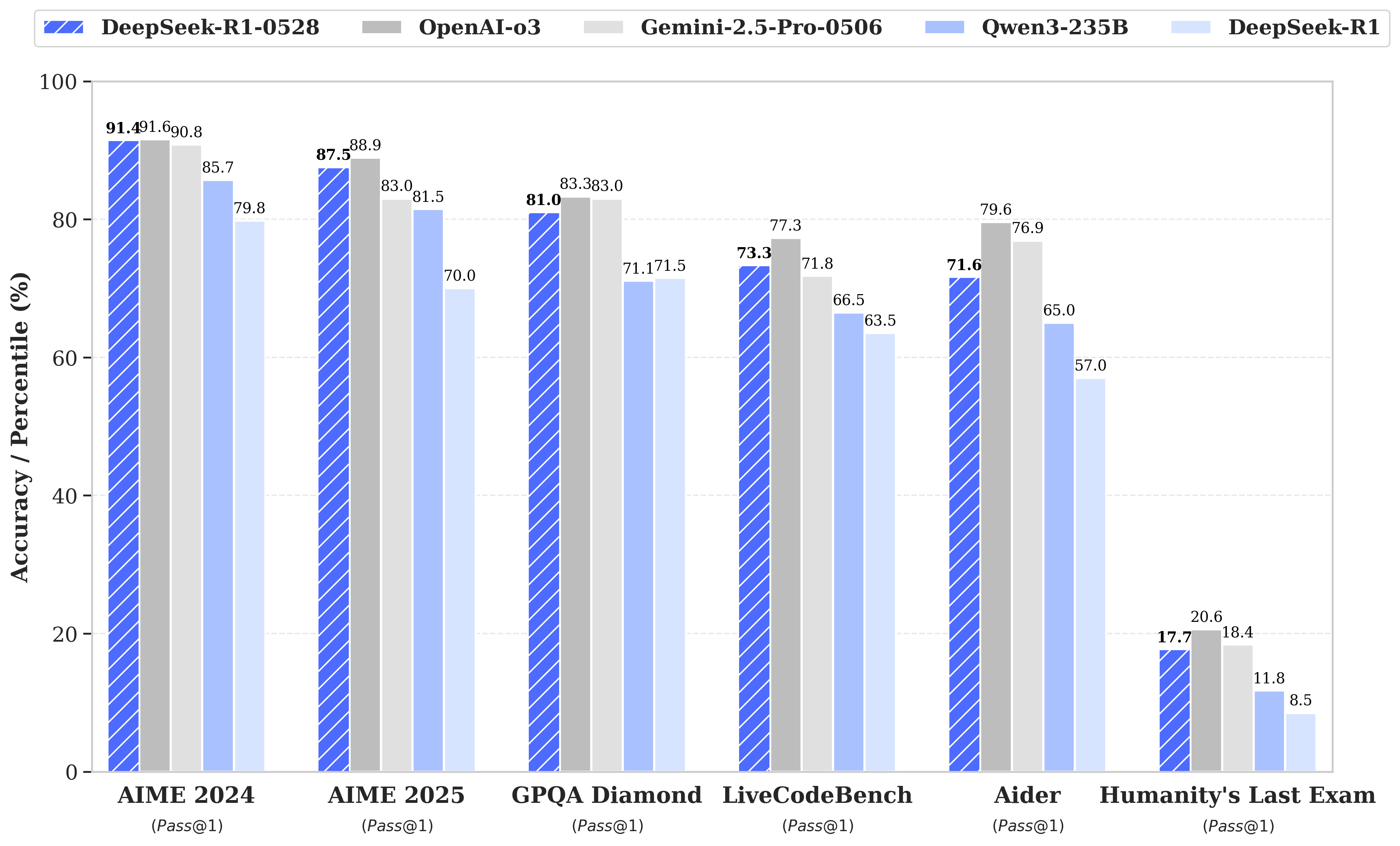
DeepSeek has released a new iteration of the R1 model, named DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
Performance
The chart below shows the performance of the full sized DeepSeek-R1 model.
License
DeepSeek-R1 is provided under the MIT license.