Documentation
Running LLMs Locally
User Interface
Command Line Interface - lms
API
Speculative Decoding
Speculative Decoding
Advanced
Speculative decoding is a technique that can substantially increase the generation speed of large language models (LLMs) without reducing response quality.
🔔 Speculative Decoding requires LM Studio 0.3.10 or newer, currently in beta. Get it here.
What is Speculative Decoding
Speculative decoding relies on the collaboration of two models:
- A larger, "main" model
- A smaller, faster "draft" model
During generation, the draft model rapidly proposes potential tokens (subwords), which the main model can verify faster than it would take it to generate them from scratch. To maintain quality, the main model only accepts tokens that match what it would have generated. After the last accepted draft token, the main model always generates one additional token.
For a model to be used as a draft model, it must have the same "vocabulary" as the main model.
How to enable Speculative Decoding
On Power User mode or higher, load a model, then select a Draft Model within the Speculative Decoding section of the chat sidebar:
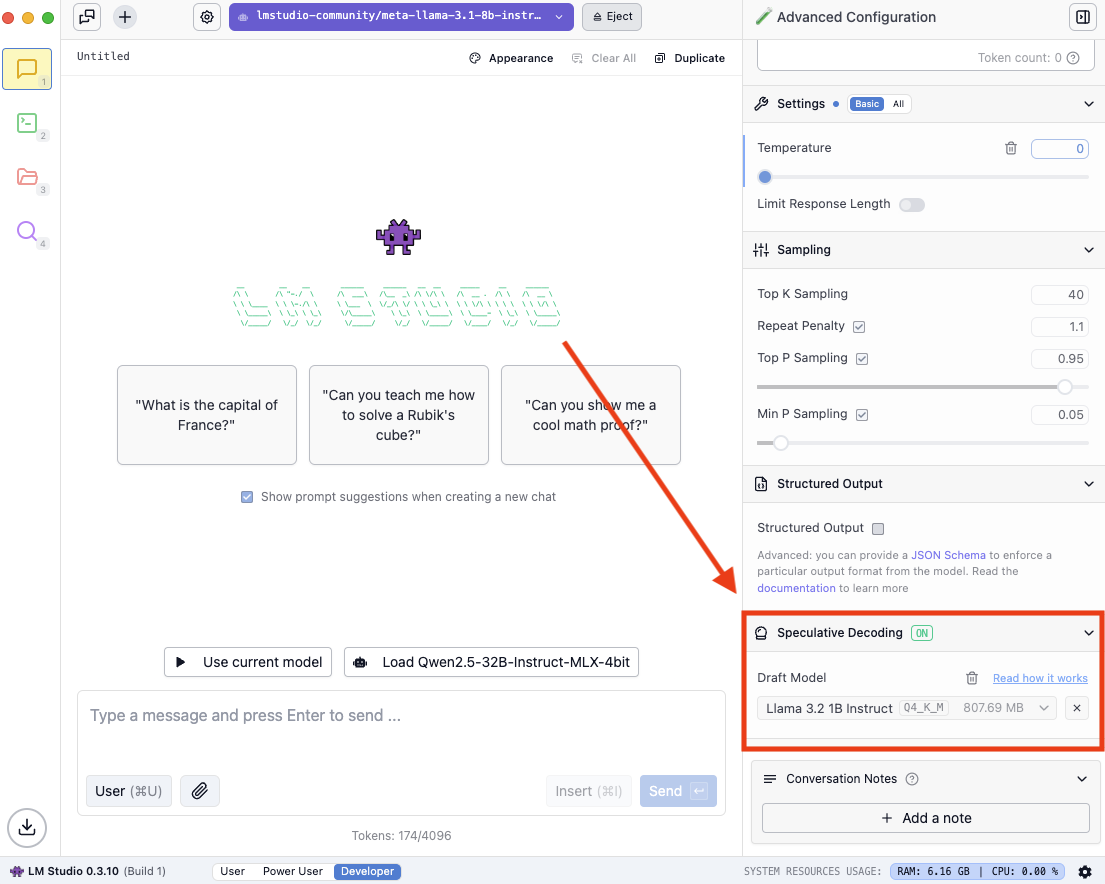
The Speculative Decoding section of the chat sidebar
Finding compatible draft models
You might see the following when you open the dropdown:
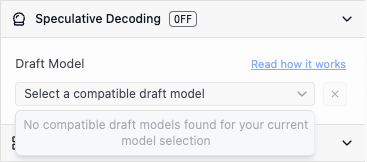
No compatible draft models
Try to download a lower parameter variant of the model you have loaded, if it exists. If no smaller versions of your model exist, find a pairing that does.
For example:
| Main Model | Draft Model |
|---|---|
| Llama 3.1 8B Instruct | Llama 3.2 1B Instruct |
| Qwen 2.5 14B Instruct | Qwen 2.5 0.5B Instruct |
| DeepSeek R1 Distill Qwen 32B | DeepSeek R1 Distill Qwen 1.5B |
Once you have both a main and draft model loaded, simply begin chatting to enable speculative decoding.
Key factors affecting performance
Speculative decoding speed-up is generally dependent on two things:
- How small and fast the draft model is compared with the main model
- How often the draft model is able to make "good" suggestions
In simple terms, you want to choose a draft model that's much smaller than the main model. And some prompts will work better than others.
An important trade-off
Running a draft model alongside a main model to enable speculative decoding requires more computation and resources than running the main model on its own.
The key to faster generation of the main model is choosing a draft model that's both small and capable enough.
Here are general guidelines for the maximum draft model size you should select based on main model size (in parameters):
| Main Model Size | Max Draft Model Size to Expect Speed-Ups |
|---|---|
| 3B | - |
| 7B | 1B |
| 14B | 3B |
| 32B | 7B |
Generally, the larger the size difference is between the main model and the draft model, the greater the speed-up.
Note: if the draft model is not fast enough or effective enough at making "good" suggestions to the main model, the generation speed will not increase, and could actually decrease.
Prompt dependent
One thing you will likely notice when using speculative decoding is that the generation speed is not consistent across all prompts.
The reason that the speed-up is not consistent across all prompts is because for some prompts, the draft model is less likely to make "good" suggestions to the main model.
Here are some extreme examples that illustrate this concept:
1. Discrete Example: Mathematical Question
Prompt: "What is the quadratic equation formula?"
In this case, both a 70B model and a 0.5B model are both very likely to give the standard formula x = (-b ± √(b² - 4ac))/(2a). So if the draft model suggested this formula as the next tokens, the target model would likely accept it, making this an ideal case for speculative decoding to work efficiently.
2. Creative Example: Story Generation
Prompt: "Write a story that begins: 'The door creaked open...'"
In this case, the smaller model's draft tokens are likely be rejected more often by the larger model, as each next word could branch into countless valid possibilities.
While "4" is the only reasonable answer to "2+2", this story could continue with "revealing a monster", "as the wind howled", "and Sarah froze", or hundreds of other perfectly valid continuations, making the smaller model's specific word predictions much less likely to match the larger model's choices.