LM Studio 0.3.9
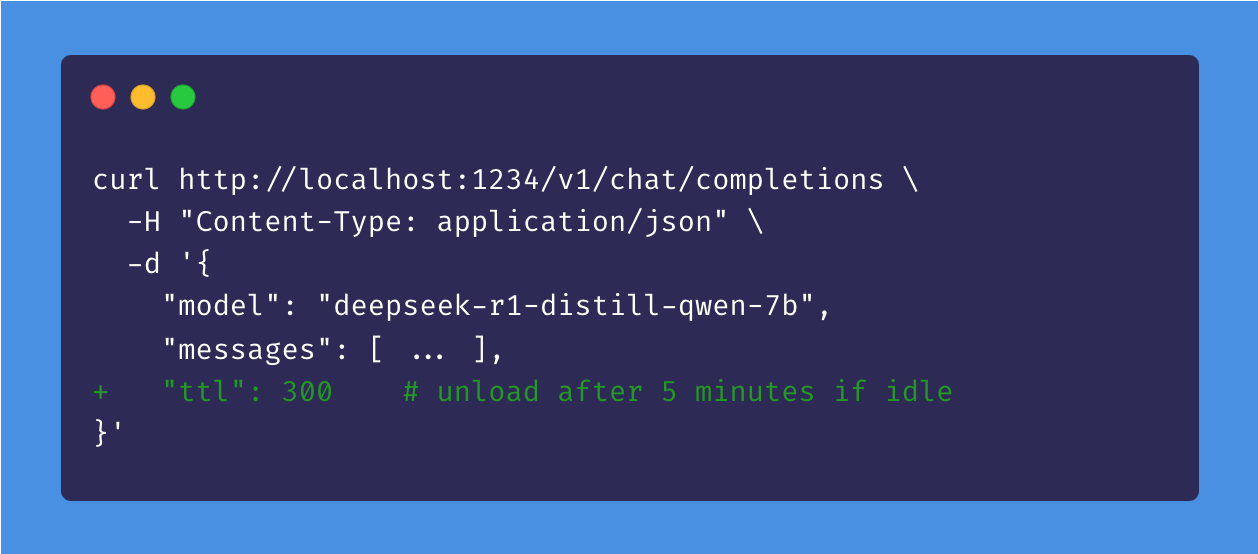
Optionally auto-unload unused API models after a certain amount of time
LM Studio 0.3.9 includes a new Idle TTL feature, support for nested folders in Hugging Face repositories, and an experimental API to receive reasoning_content in a separate field in chat completion responses.
An earlier build of 0.3.9 had a bug with streaming DeepSeek R1 chat completion responses. Please update to the latest build (5) to fix this issue.
Upgrade via in-app update, or from https://lmstudio.ai/download.
Idle TTL and Auto-Evict
Use case: imagine you're using an app like Zed, Cline, or Continue.dev to interact with LLMs served by LM Studio. These apps leverage JIT to load models on-demand the first time you use them.
Problem: When you're not actively using a model, you might don't want it to remain loaded in memory.
Solution: Set a TTL for models loaded via API requests. The idle timer resets every time the model receives a request, so it won't disappear while you use it. A model is considered idle if it's not doing any work. When the idle TTL expires, the model is automatically unloaded from memory.
You can set the TTL in seconds in the request payload, or use lms load --ttl <seconds> for command line use.
Read more in the docs article: TTL and Auto-Evict.
Separate reasoning_content in Chat Completion Responses
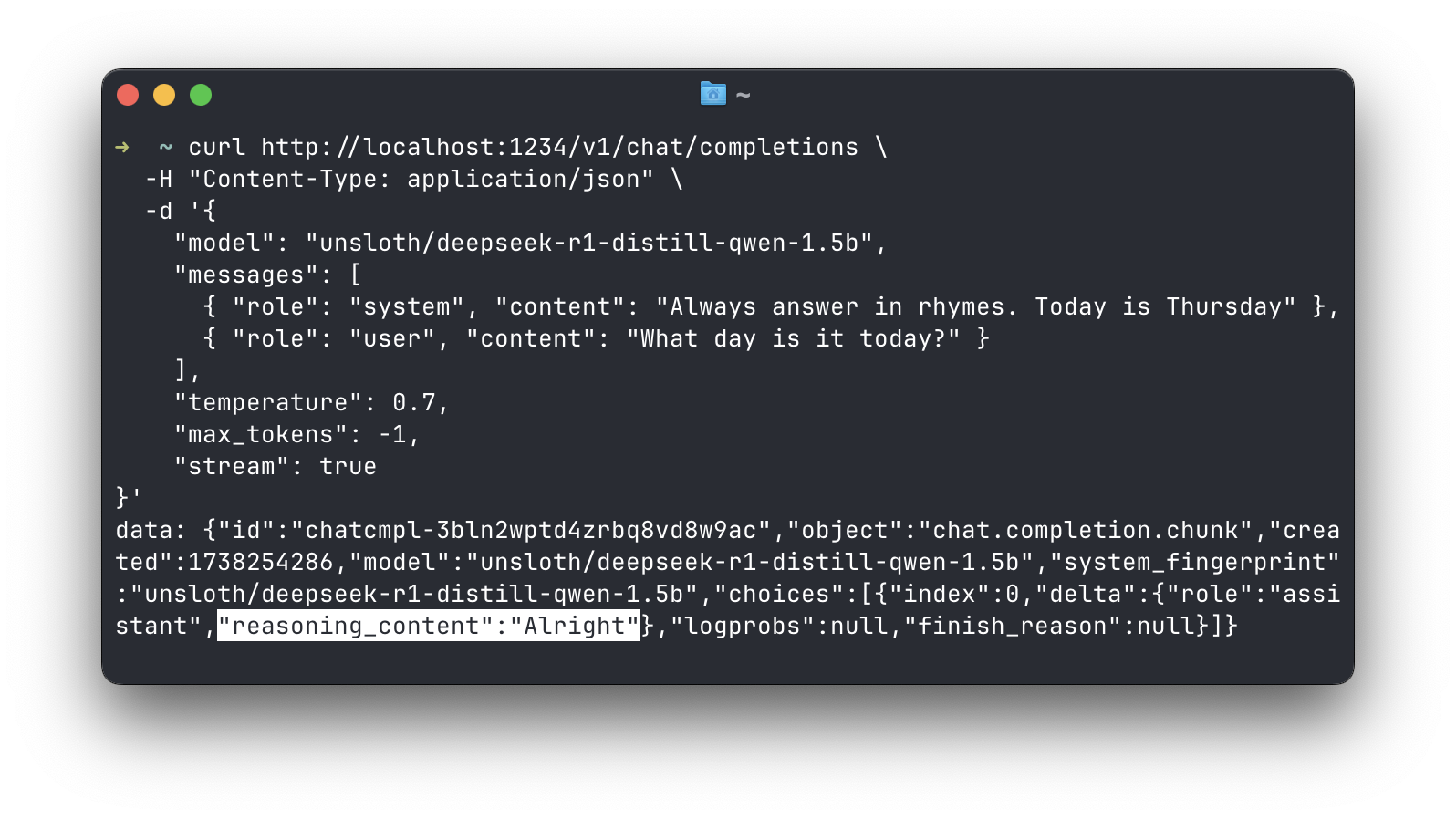
For DeepSeek R1, get reasoning content in a separate field
DeepSeek R1 models generate content within <think> </think> tags. This content is the model's "reasoning" process. In chat completion responses, you can now receive this content in a separate field called reasoning_content following the pattern in DeepSeek's API.
This works for both streaming and non-streaming completions. You can turn this on in App Settings > Developer. This feature is currently experimental.
Note: per DeepSeek's docs, you should not pass back reasoning content to the model in the next request.
Auto-Update for LM Runtimes
LM Studio supports multiple variants of llama.cpp engines (CPU-only, CUDA, Vulkan, ROCm, Metal) as well as an Apple MLX engine. These engines receive frequent updates, especially when new models are released.
To reduce the need for manually updating multiple pieces, we've introduced auto-update for runtimes. This is enabled by default, but you can turn it off in App Settings.
After a runtime is updated you will see a notification showing the release notes. You can also manage this yourself in the runtimes tab: Ctrl + Shift + R on Windows/Linux, Cmd + Shift + R on macOS.

LM Runtimes will auto update to the latest. You can turn this off in settings
Support for nested folders in Hugging Face Repositories
A long-requested feature: you can now download models from nested folders in Hugging Face repositories. If your favorite model publisher organizes their models in subfolders, you can now download them directly in LM Studio.
This makes it easy to download models like https://huggingface.co/unsloth/DeepSeek-R1-GGUF. Works for lms get <hugging face url> as well.
# Warning: this is a very large model
lms get https://huggingface.co/unsloth/DeepSeek-R1-GGUF0.3.9 - Full change log
Build 6
- Fixed "Cannot read properties of undefined" when using a text-only model in a chat with images
- Fixed a path resolution issue on Windows that caused LM Runtimes on certain machines to act unexpectedly
- CUDA model load crash, "llm_engine_cuda.node. The file cannot be accessed by the system"
- ROCm garbled model generation
- Fixed a bug where RAG messages in chats created with older versions of the app were not showing
- Fixed an Input Method Editor (IME) bug: now upon pressing Enter the message will not send unless the composition is completed
Build 5
- Fixed an API bug where
reasoning_contentsetting was not respected when streaming DeepSeek R1 chat completion responses
Build 4
- New Experimental API: send
reasoning_contentin a separate field in chat completion responses (both streaming and non-streaming)- Works for models that generate content within
<think></think>tags (like DeepSeek R1) - Turn on in App Settings > Developer
- Works for models that generate content within
Build 3
- New: Add a Chat Appearance option to auto-expand newly added Thinking UI blocks
- New: Show quick access to guardrail config when the app gives an insufficient system resources error notification
- Fixed a bug where if the non-default models directory is deleted, new models will not be indexed
- Fixed a bug in hardware detection that sometimes incorrectly filtered out GPUs in multi-GPU setups when using the Vulkan backend
- Fixed a bug in the model load UI where F32 cache types without flash attention were not recognized as a valid configuration for the llama.cpp Metal runtime
Build 2
- New: Added support for downloading models from nested folders in Hugging Face repositories
- Improved support for searching with Hugging Face URLs directly
- New: Automatically update selected Runtime Extension Packs (you can turn this off in Settings)
- New: Added an option to use LM Studio's Hugging Face proxy. This can help users who have trouble accessing Hugging Face directly
- New: KV Cache Quantization for MLX models (requires mlx-engine/0.3.0)
- My Models tab refresh: neater model names, and sidebar categories for model types
- Can toggle back to showing full file names in App Settings > General
- To see raw model metadata (previously: (i) button), right-click on the model name and choose "View Raw Metadata"
- Fixed a bug where clearing Top K in Sampling Settings would trigger an error
Build 1
- New: TTL - optionally auto-unload unused API models after a certain amount of time (
ttlfield in request payload)- For command line use:
lms load --ttl <seconds> - API reference: https://lmstudio.ai/docs/api/ttl-and-auto-evict
- For command line use:
- New: Auto-Evict - optionally auto-unload previously loaded API models before loading new ones (control in App Settings)
- Fixed a bug where equations inside model thinking blocks would sometimes generate empty space below the block
- Fixed cases where text in toast notifications was not scrollable
- Fixed a bug where unchecking and checking Structured Output JSON would make the schema value disappear
- Fixed a bug where auto-scroll while generating would sometimes not allow scrolling up
- [Developer] Moved logging options to the Developer Logs panel header (••• menu)
- Fixed Chat Appearance font size option not scaling text in Thoughts block
Even More
- Download the latest LM Studio app for macOS, Windows, or Linux.
- If you want to use LM Studio at your organization at work, get in touch: LM Studio @ Work
- For discussions and community, join our Discord server.
- New to LM Studio? Head over to the documentation: Docs: Getting Started with LM Studio.