LM Studio 0.3.6
LM Studio 0.3.6 introduces a Function Calling / Tool Use API through LM Studio's OpenAI compatibility API.
This means you can use LM Studio with any framework that currently knows how to use OpenAI tools, and utilize local models for tool use instead. This capability is in beta and we'd love to get your bug reports and feedback.
Among other new features in this 0.3.6 are support for new vision-input models: The Qwen2VL family + Qwen/QVQ (a large vision + reasoning model) in both LM Studio's MLX as well as llama.cpp engines.
Temporary Note: in-app updates from 0.3.5 (stable) will only start later this week as we transition to a new updater system. Updates are already fully operational for LM Studio 0.3.5 b10 and newer. Install LM Studio manually to get the latest.
🔔 Get notified about LM Studio releases by signing up for our mailing list.
What's new in LM Studio 0.3.6
One of the high notes of this release is that we've automated our entire build and release pipeline, which means it's going to be much easier to release new LM Studio app and engine updates. We're very excited about that.
See the full release change log below for new features and bug fixes.
Tool Calling API (Beta)
- New API: A drop-in replacement for OpenAI's Function Calling / Tool Use API
- Supports both
llama.cppandMLXmodels - Supports both streaming and non-streaming
- Supports both
- Tool use docs are available on: https://lmstudio.ai/docs/advanced/tool-use
- Use any LLM that supports Tool Use and Function Calling through the OpenAI-like API
- Qwen, Mistral, and Llama 3.1/3.2 models work well for tool use
- Included starter code within the in-app code snippets
- Improved tool call reliability through sampling configuration for both streaming and non-streaming tool use
A badge indicating a model was trained for tool use
New vision input models
- Added support for Qwen2VL (2B, 7B, 72B) and QVQ (72B) both in GGUF and MLX
- Added support for .webp images
- Added image auto resizing for vision models inputs, hardcoded to 500px width while keeping the aspect ratio
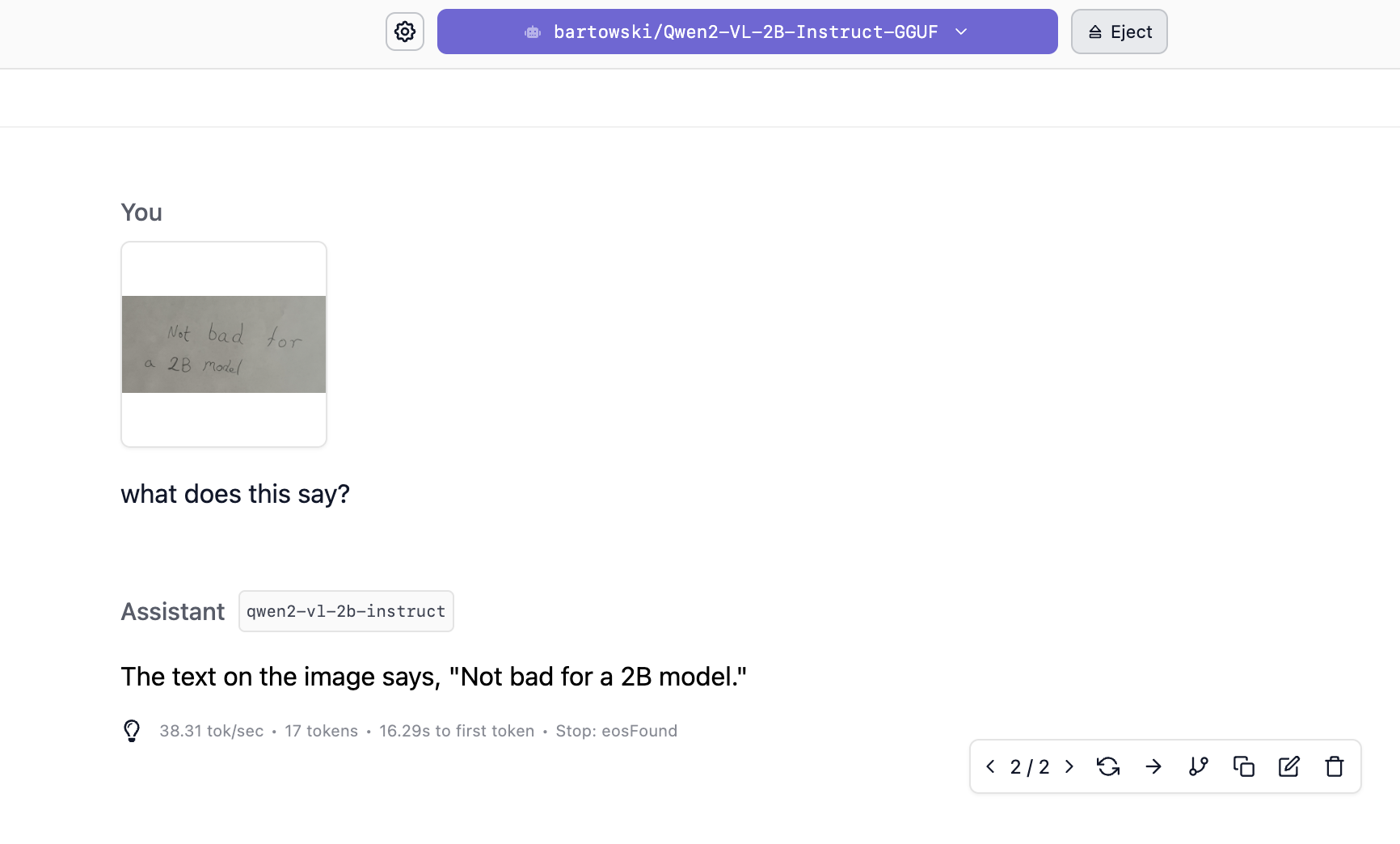
A 2B Qwen2VL vision input model recognizing simple hand writing
New and improved installer
- On Windows: you can now choose the installation drive and directory!
- On all platforms: brand new LM Studio in-app updates system
- Subscribe to either Stable or Beta updates. Beta updates will arrive more frequently.
- Note: previously release channels did not work. Now they do.
- Subscribe to either Stable or Beta updates. Beta updates will arrive more frequently.
- App updates won't redownload 100s of MBs of dependencies that don't change and generally will be much smaller and faster to download.
- And we've identified areas to make those even smaller
- Progress bar when downloading in-app updates
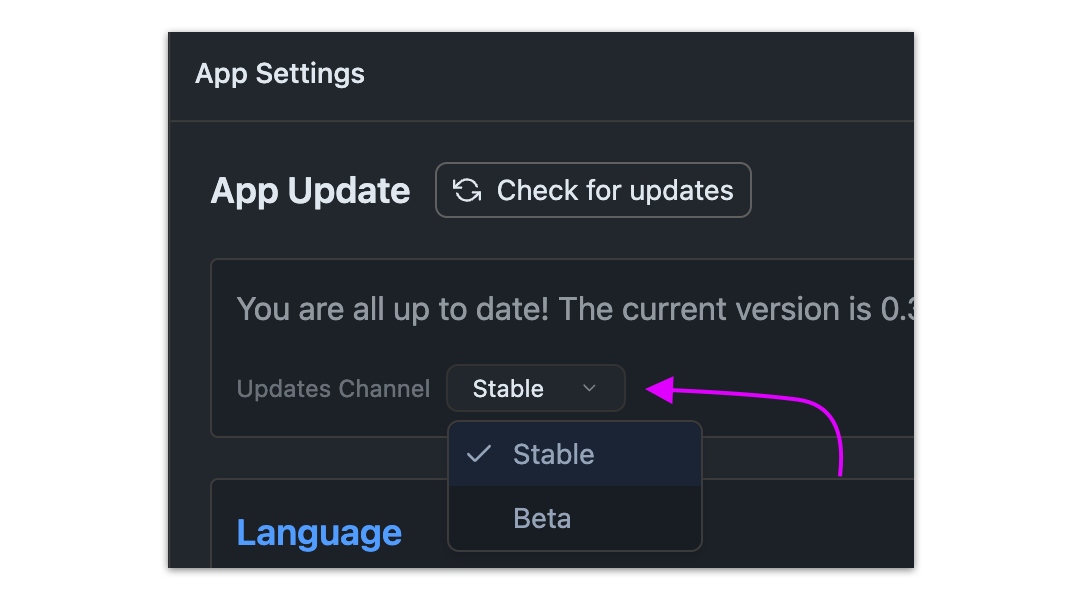
Subscribe to the Beta channel to get more frequent LM Studio updates
LM Runtimes improvements
- Improved LM Runtime release system (llama.cpp, MLX, etc)
- This was in place for a while, but we've automated nearly everything in this process.
- In-app notifications when new llama.cpp / MLX versions are available to download
- Will NOT require a full app update
- Added "Missing Libraries" runtime compatibility status that allows users to "Fix" improperly installed runtimes
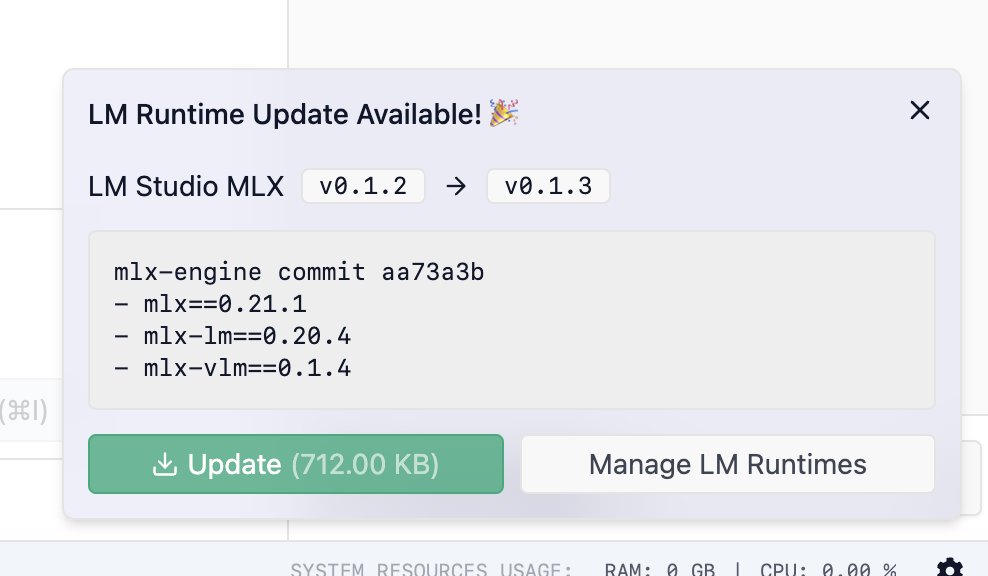
Update your llama.cpp or MLX engine as soon as updates becomes available, without waiting for LM Studio app update in most cases
UI improvements
- Chat sidebar UI improvements
- Server page UI improvements
- Show release notes in-app after an update
- Added a setting option to always use LLM to generate titles, even when generation speed is slow
MLX updates (Apple Silicon)
- Improved performance for MacOS 15
- Improved performance for VLMs
- Improved performance for long context generation
- Bump mlx-engine dependencies versions:
mlx==0.21.1,mlx_lm==0.20.4,mlx_vlm==0.1.4 - Support for 3-bit and 6-bit quantization for MLX models
Developer Experience
- New in-app "Quick Docs" with code snippets and tool use examples (top right corner)
- Opens in a new window for side-by-side usage in LM Studio
- Improved error reporting in the server API
- Pop out the server logs to a new window by pressing
cmd/ctrl+shift+J- Works while in the chat page too
- For power users: LM Studio's home directory moved from the historical
~/.cache/lm-studioto the new~/.lmstudio.- This will only take effect for first-time installs.
- If you already have data in
~/.cache/lm-studiothe app will NOT attempt to move it.
Bug fixes
- Fixed "inputConfig required to render jinja prompt" when using the
/completionsAPI endpoint - Fixed first model download during onboarding showing blank screen
- Fixed runtimes not being set up properly when app installed for All Users on Windows
- Bugfix: make
tool_call_idoptional - Fixed a bug with jinja template processing for Qwen2VL and other models
- Fixed a bug where newer LM Runtimes weren't selected after an update
- Fixed clicking in chat name field while editing cancels the rename
- [Mac] Fixed error when sending an image to vision enabled models
- Fixed tool-call messages having "content": null are erroneously rejected
- Fixed secondary click on presets sometimes not working
- Fixed RAG not working
- Fixed a bug where chats and folders couldn't be dragged to the root of the sidebar
- Fixed a memory leak when counting tokens/using embedding models
- Fixed installer being blurry on high DPI screens
- Fixed when a new runtime is installed, the search filter for models is not updated
- Fixed searching "Qwen VL" does not give correct results
- Fixed a issue where models cannot be loaded when the app is still initializing
- Fixed a issue where the chats page would softlock
- Fixed a issue where the length of the scroll bar of the chat side bar would be out of sync with content height
- Fixed runtime deletion not working
- Fixed a rare bug will delete chats can sometimes softlock the app
- Fixed lms load command
- Fixed lms unload and lms status not working with embeddings
- Fixed request logging when verbose logging is on (server)
- Fixed some requests/responses are not redacted when logging prompts and responses are off
- Fixed download resuming
- Fixed more accessibility labels on UI elements
- Fixed drag and drop file attachment not working
- [MLX] Fixed bug which degraded performance for certain models
- Fixed app not launching on some Linux distributions
- Fixed accessibility button labels (previously showing Object object)
- Fixed a bug where models without chat templates, including embedding models, could not be indexed
- Fixed passing an empty or null tools array in the API request is treated as no tools provided
- Fixed passing an empty or null tool_calls array in assistant messages in the API request is treated as the model making no cool calls
- Fix for file attachments causing an error
- Fix for long chat names pushing chat action buttons in the sidebar
- Candidate fix for huggingface model search, download never reachable from within the app ("fetch failed")
- Fix for pasting text from Microsoft Word giving an error about pasting an image
- Fix for structured output for GGUF models lmstudio-bug-tracker/issues/173
- Fix for machines with 1-2 CPU cores getting an error about CPU threads too low
- Fixes to in-app update when service mode is enabled
- Fixes to JIT loading across client application lifetime
Even More
- Download the latest LM Studio app for macOS, Windows, or Linux.
- If you want to use LM Studio at your organization at work, get in touch: LM Studio @ Work
- For discussions and community, join our Discord server.
- New to LM Studio? Head over to the documentation: Docs: Getting Started with LM Studio.