LM Studio 0.3.28
LM Studio 0.3.28 is now available as a stable release. Update in‑app or download the latest version.
New: Model variant picker in My Models
When you download a staff picked model, you can often choose between multiple variants of the model. For example, you might be able to choose an MLX and a GGUF variant of the same model, or between different quantizations (e.g. 4-bit, 6-bit, or 8-bit).
Starting in 0.3.28, you can now quickly select which variant will be used by default when you load the model, either in the app, API calls, or with the CLI.
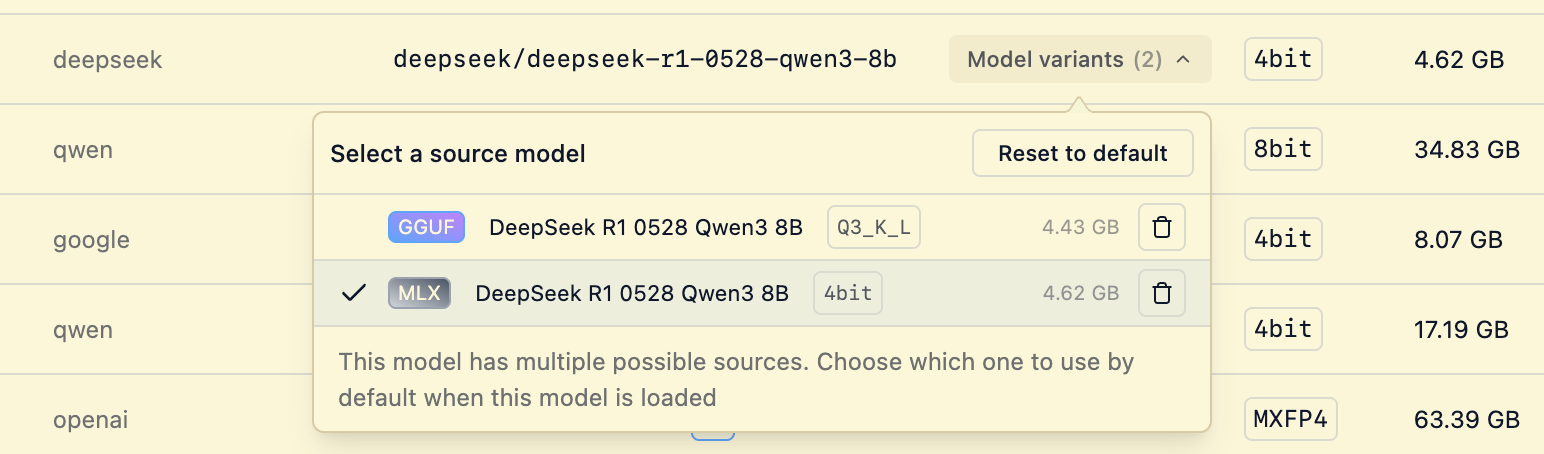
Quickly select which model variant will be used by default
This will work for any model.yaml with multiple sources, including models you create yourself. See more in the docs.
Improved RAM/VRAM usage estimation
- Significantly improved RAM/VRAM usage estimation in the following cases:
- Mixed quantizations
- Models with inaccurate parameter labels in metadata
- Non‑transformer models
Misc UI polish
Fixed lots of UI flickers on My Models page, and fixed model parameter counts not displaying for some models.
0.3.28 - Release Notes
Build 2
- Fix displaying model parameter counts in My Models and model picker
- Improved Qwen format tool call reliability with llama.cpp engines
- Fix UI theme resetting to 'Auto' after update to 0.3.28 (fixes issue in build 1)
Build 1
- New in My Models: ability to quickly select which model variant will be used by default
- Significantly improved RAM/VRAM usage estimation for models that have mixed quantizations
- Significantly improved RAM/VRAM usage estimation for models that have inaccurate parameter labels in their metadata
- Significantly improved RAM/VRAM usage estimation for non-transformer models
- Fixed a bug where models loaded via the CLI would not respect global GPU settings
- Fix some flickering UI interactions on My Models page, and collapse indexer warnings under a new status button
- Fix a bug where citations count badge with over 10 would clip text
- Fix inconsistency in quantization badge text alignment
Resources
- We are hiring! Check out our careers page for open roles.
- Download LM Studio: lmstudio.ai/download
- Report bugs: lmstudio-bug-tracker
- X / Twitter: @lmstudio
- Discord: LM Studio Community