LM Studio 0.3.10: 🔮 Speculative Decoding
Llama 8B as main and Llama 1B as draft, both MLX 4 bit on M3 MacBook Pro
We're thrilled to introduce Speculative Decoding support in LM Studio's llama.cpp and MLX engines!
Speculative Decoding is a technique that can speed up token generation by up to 1.5x-3x in some cases.
Upgrade LM Studio to 0.3.10 via in-app update, or from https://lmstudio.ai/download.
Speculative Decoding
Speculative decoding is an inferencing optimization technique pioneered by works like Fast Inference from Transformers via Speculative Decoding by Leviathan et al., and Accelerating Large Language Model Decoding with Speculative Sampling by Chen et al. It can be viewed as a sort of a speculative execution optimization you might find in modern CPUs, but applied to LLMs inferencing.
In both LM Studio's llama.cpp and MLX engines, Speculative Decoding is implemented using a combination of 2 models: a larger LLM ("main model"), and a smaller / faster "draft model" (or "speculator"). The original llama.cpp implementation was authored by Georgi Gerganov, and MLX's by Benjamin Anderson and Awni Hannun. These implementations are continually improved upon by the open source community.
How it works
The draft model is being run first, quickly predicting the next few tokens as a "draft" generation. Right afterwards, the draft generation tokens are either confirmed or rejected by the main model. Only tokens that would have been generated by the main model are accepted. This results in potential speedups (when enough tokens are accepted) without any degradation in quality. In cases where tokens are rejected more often than not, you will likely see decreased total generation speed! The choice of models is important for achieving best results.
Performance Stats
LM Studio + MLX engine (Apple M3 Pro, 36GB RAM)
| Prompt | Main Model | Draft Model | w/o Spec. | w/ Spec. | tok/sec speedup |
|---|---|---|---|---|---|
| "Write a quicksort algorithm in Python. Write code only." | Qwen2.5-32B-Instruct-MLX-4bit | Qwen2.5-0.5B-Instruct-4bit | 7.30 tok/sec | 17.74 tok/sec | 2.43x |
| "Explain the Pythagorean theorem" | Meta-Llama-3.1-8B-Instruct-4bit | Llama-3.2-1B-Instruct-4bit | 29.65 tok/sec | 50.91 tok/sec | 1.71x |
| "Plan a 1 day trip to DC" | Meta-Llama-3.1-8B-Instruct-4bit | Llama-3.2-1B-Instruct-4bit | 29.94 tok/sec | 51.14 tok/sec | 1.71x |
LM Studio + CUDA llama.cpp engine (NVIDIA RTX 3090 Ti 24GB VRAM, Intel Core Ultra 7 265K CPU, 32GB RAM)
| Prompt | Main Model | Draft Model | w/o Spec. | w/ Spec. | tok/sec speedup |
|---|---|---|---|---|---|
| "Write a quicksort algorithm in Python. Write code only." | Qwen2.5-32B-Instruct-GGUF (Q4_K_M) | Qwen2.5-0.5B-Instruct-GGUF (Q4_K_M) | 21.84 tok/sec | 45.15 tok/sec | 2.07x |
| "Explain the Pythagorean theorem" | Meta-Llama-3.1-8B-Instruct-GGUF (Q8_0) | Llama-3.2-1B-Instruct-GGUF (Q4_0) | 50.11 tok/sec | 68.40 tok/sec | 1.36x |
| "Plan a 1 day trip to DC" | Meta-Llama-3.1-8B-Instruct-GGUF (Q8_0) | Llama-3.2-1B-Instruct-GGUF (Q4_0) | 46.90 tok/sec | 49.09 tok/sec | 1.05x |
Using Speculative Decoding in your chats
In LM Studio 0.3.10, you will find a new sidebar section for Speculative Decoding. Once you have a main model loaded (cmd/ctrl + L), you'll see compatible options for draft model in the new draft model selector.
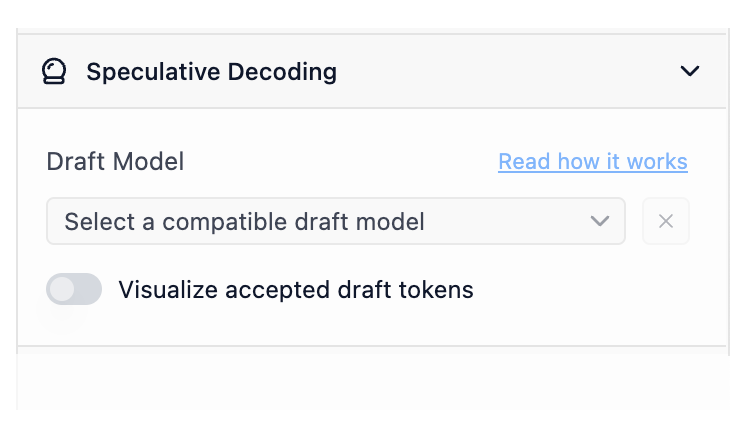
The new draft model selector in the config sidebar
Draft model compatibility
For a model to be used as a draft model for another model, they need to be "compatible". At a high level, for the draft model to be effective it must be able to generate from the same possible tokens the larger model would. Practically speaking, both models should share sufficiently similar vocabulary (the totality of tokens the model "knows" about) and tokenizer characteristics. LM Studio automatically checks whether your models are compatible for each other for the purposes of speculative decoding.
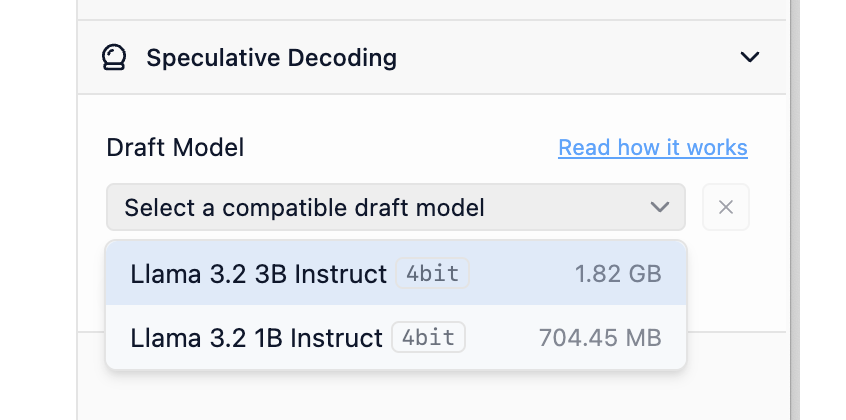
LM Studio will automatically index the compatibility of possible main and draft model pairs.
Visualize accepted draft tokens
Turn on accepted draft token visualization to see colorized tokens indicating whether they were generated from the draft model or the main model. The more green, the better.
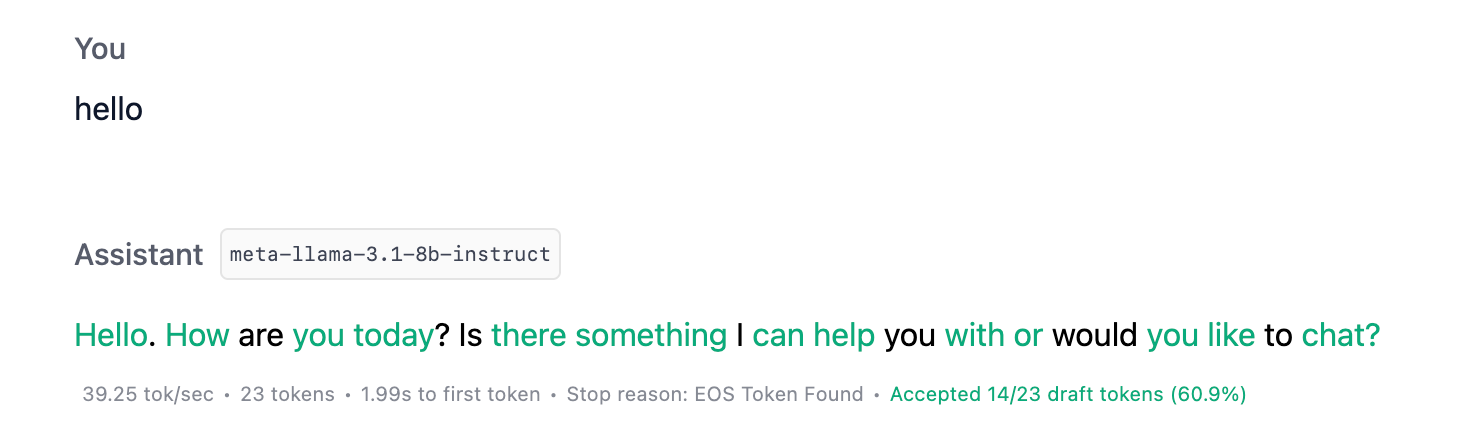
Turn on draft token acceptable visualization to understand more about draft model performance
Using Speculative Decoding via API
You can also use speculative decoding via LM Studio's local server. When enabled, you'll get back rich generation stats including new fields related to speculative decoding.
"stats": { "tokens_per_second": 15.928616628606926, "time_to_first_token": 0.301, "generation_time": 1.382, "stop_reason": "stop", "draft_model": "lmstudio-community/llama-3.2-1b-instruct", "total_draft_tokens_count": 12, "accepted_draft_tokens_count": 10, "rejected_draft_tokens_count": 0, "ignored_draft_tokens_count": 2 }
Stats returned from LM Studio's REST API. Learn more about it here.
Option 1: Set a draft model in the Server UI
Similar to the chat, you can set a draft model in the config sidebar. Once set, requests targeting this model will leverage speculative decoding using the draft model you selected.
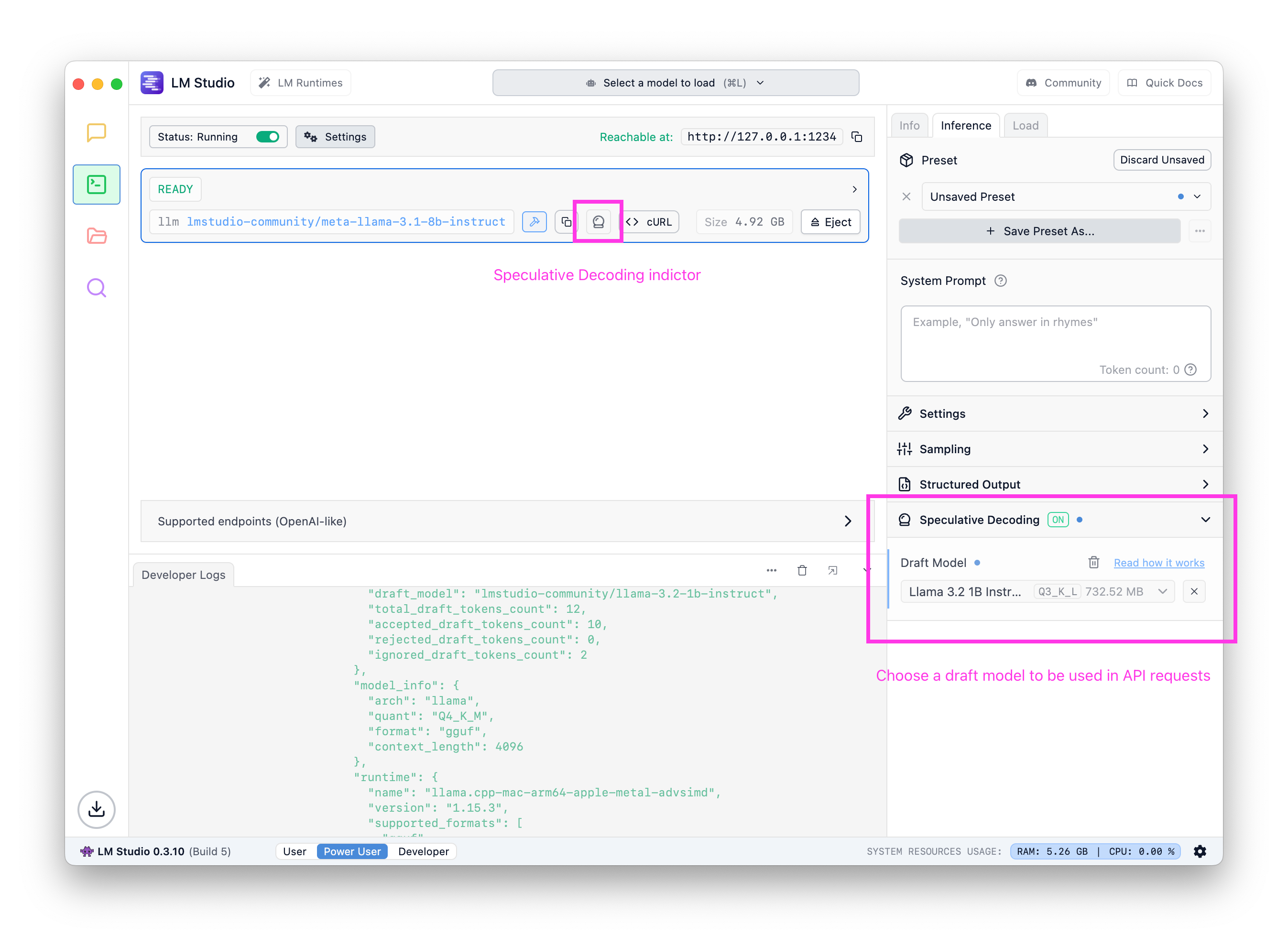
Set a default draft model for any given main model in the server UI
Option 2: draft_model in your request
You can also provide the draft model key as a part of your request payload. Learn more about JIT loading.
curl http://localhost:1234/api/v0/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1-distill-qwen-7b", + "draft_model": "deepseek-r1-distill-qwen-0.5b", "messages": [ ... ] }'
You can use Speculative Decoding both through LM Studio's OpenAI compatibility API and the REST API.
How to use Speculative Decoding effectively
Read the documentation article: Speculative Decoding.
As a rule of thumb, aim to pair a large model with a smaller one. The draft model should be much smaller than the main model, and from the same family. For example, you can use Llama 3.2 1B as a draft model for Llama 3.1 8B.
Note: as of LM Studio 0.3.10, the system will try to offload the draft model entirely onto the GPU, if one exists. The main model GPU settings are configurable as usual.

Many such cases. For some tasks, and some models, you can get more than 2x speedups with no degradation in quality
When to expect worse performance
Two main factors will lead to worse performance: draft model too large compared with your available resources, and low draft acceptance rates. To avoid the former, always use draft models that are much smaller than the main model by comparison. The latter is model and prompt dependent. The best way to undertand the possible tradeoffs of speculative decoding is to try it for yourself on the tasks you care about.
Finding compatible draft models
Since not all models are compatible with each other, it's important to identify models that can work together as a draft and main model.
An easy approach is using a large and small variant of the same model family, as illustrated in the table below:
| Example Main Model | Example Draft Model |
|---|---|
| Llama 3.1 8B Instruct | Llama 3.2 1B Instruct |
| Qwen 2.5 14B Instruct | Qwen 2.5 0.5B Instruct |
| DeepSeek R1 Distill Qwen 32B | DeepSeek R1 Distill Qwen 1.5B |
Pro tip: configure a default draft model in 📂 My Models
If you know you always want to use a given draft model, you can configure it in My Models as a per-model default. Once you do this, the system will enable speculative decoding using your chosen draft model when this model is used (either via the chat or API).
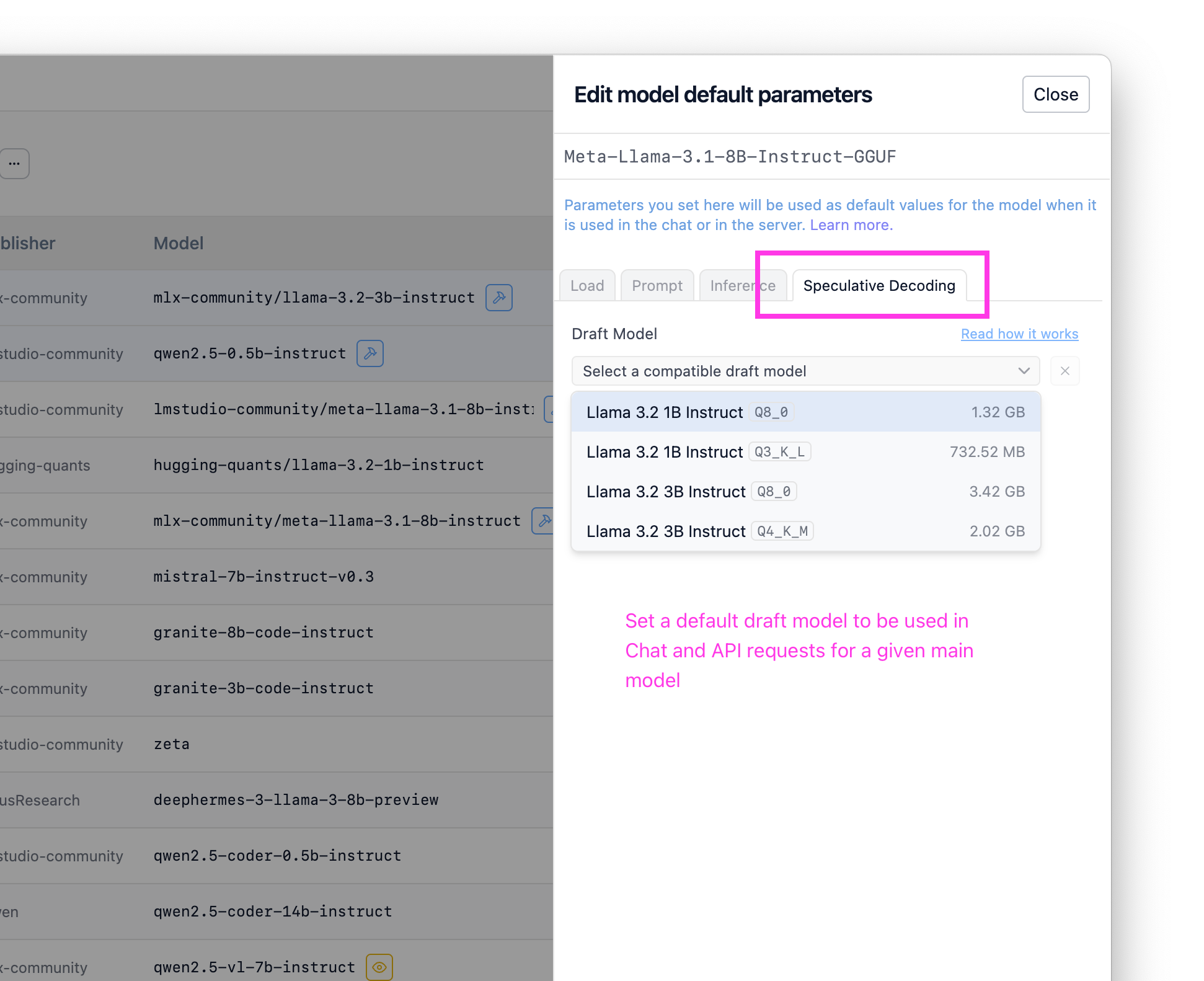
Set a default draft model for any given main model in My Models
Advanced Resources
We've compiled a few extra resources for those of you who want to dig deeper!
Interested in this kind of work? We're hiring. Shoot over your resume + note about a project you're proud of to [email protected].
Papers:
- Fast Inference from Transformers via Speculative Decoding
- Accelerating Large Language Model Decoding with Speculative Sampling
- SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification
- Accelerating LLM Inference with Staged Speculative Decoding
Compatibility check implementations
The following are excerpts from llama.cpp and MLX showing the current implementations for checking speculative decoding compatibility between models.
# The current MLX compat check is very minimal and might evolve in the future
def is_draft_model_compatible(self, path: str | Path) → bool:
path = Path(path)
draft_tokenizer = mlx_lm.tokenizer_utils.load_tokenizer(path)
if draft_tokenizer.vocab_size != self.tokenizer.vocab_size:
return False
return True
Sources:
llama.cpp: ggml-org/llama.cppMLX: lmstudio-ai/mlx-engine
0.3.10 - Full change log
**Build 6** - Fixed an issue where first message of tool streaming response did not include "assistant" role - Improved error message when trying to use a draft model with a different engine. - Fixed a bug where speculative decoding visualization does not work when continuing a message. **Build 5** - Bug fix: conversations would sometimes be named 'Untitled' regardless of auto naming settings - Update MLX to enable Speculative Decoding on M1/M2 Macs (in addition to M3/M4) - Fixed an issue on Linux and macOS where child processes may not be cleaned up after app exit - [Mac][MLX] Fixed a bug where selecting a draft model during prediction would cause the model to crash **Build 4** - New: Chat Appearance > "Expand chat container to window width" option - This option allows you to expand the chat container to the full width of the window - Fixed RAG not working due to "path must be a string" **Build 3** - The beginning and the end tags of reasoning blocks are now configurable in My Models page - You can use this feature to enable thinking UI for models that don't use `<think>` and `</think>` tags to denote reasoning sections - Fixed a bug where structured output is not configurable in My Models page - Optimized engine indexing for reduced start-up delay - Option to re-run engine compatibility checks for specific engines from the Runtimes UI - [Mac] Improved reliability of MLX runtime installation, and improved detection of broken MLX runtimes **Build 2** - Fixed a case where the message about updating the engine to use speculative decoding is not displayed - Fixed a bug where we sometimes show "no compatible draft models" despite we are still identifying them - [Linux] Fixed 'exit code 133' bug (reference: https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues/285) **Build 1** - New: 🔮 Speculative Decoding! (for llama.cpp and MLX models) - Use smaller "draft model" to achieve generation speed up by up to 1.5x-3x for larger models. - Works best when combining very small draft model + large main model. The speedup comes without _any_ degradation in quality. - Your mileage may vary. Experiment with different draft models easily to find what works best. - Works in both chat UI and server API - Use the new "Visualize accepted draft tokens" feature to watch speculative decoding in action. - Turn on in chat sidebar. - New: Runtime (cmd/ctrl + shift + R) page UI - Auto update runtimes only on app start up - Fixed a bug where multiple images sent to the model would not be recognized
Even More
- Download the latest LM Studio app for macOS, Windows, or Linux.
- If you want to use LM Studio at your organization at work, get in touch: LM Studio @ Work
- For discussions and community, join our Discord server.
- New to LM Studio? Head over to the documentation: Docs: Getting Started with LM Studio.